2436
High performance GPU enabled GRAPPA reconstruction using CUDA1Electrical Engineering, COMSATS University Islamabad, Islamabad, Pakistan
Synopsis
GRAPPA is a parallel MRI technique that enables accelerated data acquisition using multi-channel receiver coils. However, processing a large data limits the performance of GRAPPA in terms of reconstruction time. This work presents a new GPU-enabled-GRAPPA reconstruction method using optimized CUDA kernels, where multiple threads simultaneously communicate and cooperate to perform: (i) parallel fittings of GRAPPA kernel on auto-calibration signals; (ii) parallel estimations of reconstruction coefficients; (iii) parallel interpolations in under-sampled k-space. In-vivo results of 8-channel, 1.5T human head dataset show that the proposed method speeds up the GRAPPA reconstruction time up to 15x without compromising the image quality.
INTRODUCTION
GRAPPA (Generalized Auto-calibrating Partially Parallel Acquisition) is a robust parallel image reconstruction MRI (pMRI) method that employs accelerated MR data acquisition using multichannel receiver coils1. However, recent advancements in pMRI with large number of receiver coils suggest that the practical gains in the performance of parallel imaging using GRAPPA are offset by the long image reconstruction times2. This is primarily due to the fact that the conventional GRAPPA reconstruction process seeks3: (i) multiple sequential GRAPPA kernel fittings on the auto-calibration signals (ACS lines) to collect calibration data in the source $$$\left(S_{{m}\times{n}}\right)$$$ and target matrices $$$\left(T_{{m}\times{l}}\right)$$$, where $$${m}\gg{n}$$$; (ii) estimation of GRAPPA weight sets $$$\left(W_{{n}\times{l}}\right)$$$ by finding least squares solution to a large over-determined system of linear equations i.e. $$$\widehat{w}=\min_{w}||Sw-t||^2$$$; (iii) iterative convolutional kernel fittings on the under-sampled k-space data of each receiver coil, to reconstruct the missing k-space data.
In this abstract, a new parameterizable GPU-enabled-GRAPPA reconstruction method is presented to meet the rising demands of fast image processing in real-time clinical applications. The proposed method employs a parallel architecture of optimized CUDA (Compute Unified Device Architecture) kernels, to exploit the fine grained parallelism of GRAPPA reconstruction process. Moreover, the proposed method ensures the scalability of GRAPPA reconstruction process for an arbitrary number of ACS lines and variable GRAPPA kernel sizes.
METHOD
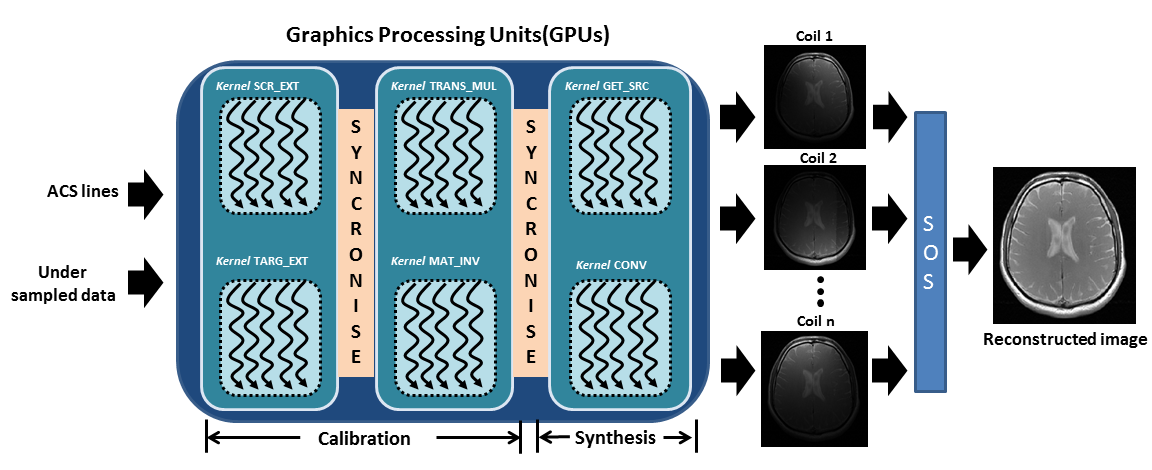
The proposed architecture of the GPU-enabled-GRAPPA reconstruction is featured with the execution of six optimized CUDA kernels as shown in the Figure 1, where kernel_SRC_EXT, kernel_TARG_EXT, kernel_TRANS_MUL and kernel_MAT_INV constitute the GRAPPA calibration phase while kernel_GET_SRC and, kernel_CONV constitute the GRAPPA synthesis phase.
During the calibration phase, kernel_SRC_EXT and kernel_TARG_EXT perform concurrent GRAPPA kernel fittings on the ACS lines to collect the calibration data points in the source $$$\left(S_{{m}\times{n}}\right)$$$ and target $$$\left(T_{{m}\times{l}}\right)$$$ matrices, while kernel_TARNS_MUL and kernel_MAT_INV estimate the GRAPPA weight sets $$$\left(W\right)$$$ by solving $$$W_{n\times{l}}=\left({S_{{n}\times{m}}^{'}\times{S_{m\times{n}}}}\right)^{-1}\times{S_{{m}\times{n}}\times{T_{{m}\times{l}}}}$$$ on the GPU. In the proposed method, parallelized Gauss Jordan algorithm4 and the concepts of tile partitioning5 are used to efficiently perform complex matrix inversion i.e. $$$W_{n\times{l}}=\left({S_{{n}\times{m}}^{'}\times{S_{m\times{n}}}}\right)^{-1}$$$ and complex matrix-matrix multiplications on the GPU.
In the synthesis phase, kernel_GET_SRC and kernel_CONV interpolate the missing phase encode lines in the k-space of each receiver coil, where kernel_GET_SRC performs parallel kernel fittings to extract a new set of source matrices $$$\left(S_{new}\right)$$$ from the acquired under-sampled k-space data of each receiver coil. Subsequently, kernel_CONV performs parallel convolutions (using estimated weight $$$W$$$ sets and $$$S_{new}$$$), for concurrent interpolation of the under-sampled k-space data in each receiver coil. Once the fully sampled k-space has been restored for all the receiver coils, a set of uncombined images for each receiver coil is constructed using Fourier Transform. The composite image is then formed using the sum-of-square reconstruction of the individual coil images. To validate the performance of the proposed method, several experiments have been performed using 8-channel in-vivo human head dataset acquired on 1.5T scanner, St Mary’s Hospital London. Acquisition details and hardware specifications used in our experiments are given in Table 1.
For a comparison between the proposed GPU-enabled-GRAPPA architecture and the conventional GRAPPA reconstruction (Visual C++), the computation time and reconstruction accuracy (in terms of SNR) is evaluated for various GRAPPA kernel sizes (e.g. [2x3] and [4x7]) and ACS lines (e.g. 32 and 48).
RESULTS & DISCUSSION
The
performance of the proposed GPU-enabled-GRAPPA architecture is evaluated by
profiling the execution times of the two main phases of the algorithm i.e.
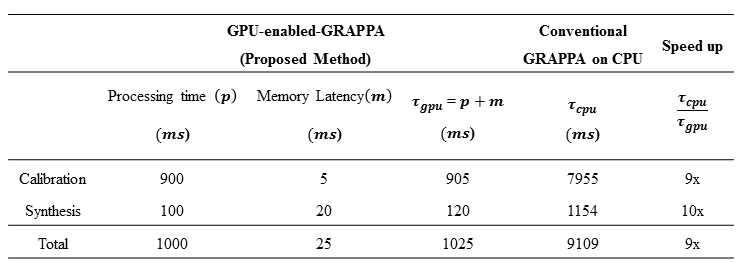
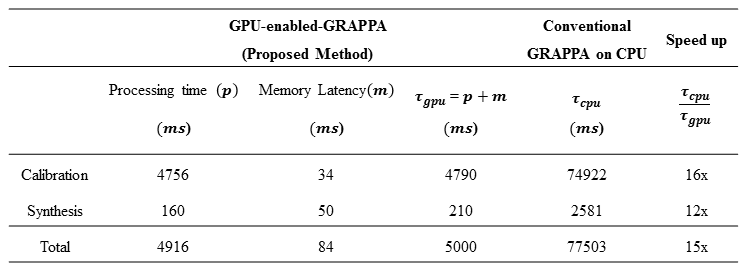
calibration phase and synthesis phase, as shown in Table 2 and Table 3. The
results show that the proposed frame work is scalable to different GRAPPA parameter
settings (i.e. ACS lines and kernel sizes) and significantly reduces the
latency of the calibration and synthesis phases, thereby providing upto $$$15x$$$ speedup (for in-vivo
8-channel, 1.5T human
head data) in the total reconstruction time. Moreover, the results signify that
the proposed method is a suitable choice to accelerate the GRAPPA
reconstruction process as the thread creation and memory transfer overheads are
negligible (e.g. a memory latency is 0.017% of the total reconstruction time (Table 3)).
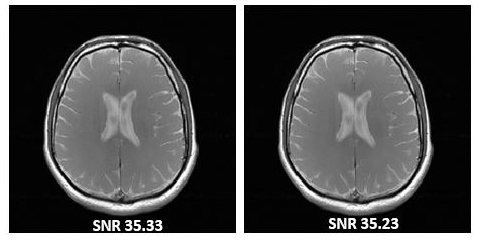
The reconstructed images
of the proposed GPU-enabled-GRAPPA reconstruction and conventional GRAPPA on
CPU are shown in Figure 2. The results
show that there is no significant difference in the visual quality and SNR of
the reconstructed images using the proposed architecture as compared to the conventional
GRAPPA reconstruction.CONCLUSION
This work presents a new parameterizable architecture of optimized CUDA kernels for low-latency GPU-enabled-GRAPPA reconstruction. The results show that the proposed method leverages optimizations to GRAPPA calibration and synthesis phases to obtain high-speed reconstructions without compromising the image quality.Acknowledgements
We are grateful to NVIDIA's Academic Programs Team, for providing us high performance GPU platforms under NVIDIA Academic GPU grantsReferences
[1] M. A. Griswold, et al. Magn Reson Med, 47(6):1202–1210, 2002
[2] Seriberlich N, et al. J Magn Reson Imag, 36(1): 55-72, 2012
[3] L. Ying, et al. Magn Reson Imag, 74(1): 71-80, 2014
[4] Sharma, Girish, et al. Computers & Structures, 32(1):31–37, 2013
[5] Ryoo, Shane, et al 13th ACM SIGPLAN, 32(1): 54–135, 2018
Figures