1588
FPGA-based coprocessor for real-time SENSE reconstruction: Design and Implementation1Electrical Engineering, COMSATS University Islamabad, Islamabad, Pakistan
Synopsis
In real-time clinical settings, high speed systems have become imperative to meet the large data processing requirements of parallel MRI algorithms e.g. SENSE. Field-Programmable-Gate-Arrays (FPGAs) have recently emerged as a viable solution to adhere the rising demands of fast data processing by exploiting the inherent parallelism of SENSE reconstruction algorithm. This paper presents the first design effort to implement high performance 32-bit floating-point FPGA-based coprocessor for real-time SENSE reconstruction using high-level-synthesis (HLS) frame work. In-vivo results of 8-channel 1.5T human-head dataset show that the proposed system speeds up the image reconstruction time up to 1000x without compromising the image quality.
INTRODUCTION
SENSE (Sensitivity Encoding) is a robust parallel image reconstruction method that employs accelerated data acquisition using multi-channel receiver coils1. However, SENSE reconstruction process involves multiple sequential passes on a general-purpose computer, to iteratively unfold and combine the aliased images from each receiver coil, thus making the image reconstruction time impractically long in many clinical settings2. Multicore-CPUs and Graphical-Processing-Units (GPUs) are capable to support large processing requirements of SENSE algorithm2,3. However, the complier overheads of executing multi-threaded components and memory transfer delays may limit their performance in real-time MRI. Recently, a solution to this increasing complexity of parallel MRI came with the introduction of FPGA technology4. Modern FPGA devices support real-time MR image processing due to their advanced capabilities of reconfigurable computing and tremendous energy efficiency as compared to high end CPUs and GPUs, thus making them a suitable choice for portable MRI scanners. With these benefits, there is a growing adoption of High-Level-Synthesis (HLS) for rapid development of sophisticated applications on FPGAs4. HLS tools adopt a new development flow to design FPGA-based digital systems, which raise the design effort to higher abstraction level beyond Register-Transfer-Logic (RTL)4. Recently, RTL implementation of 16-bit fixed-point architecture for real-time SENSE reconstruction has been presented5. However, the proposed architecture has the capability to perform only fixed-point arithmetic operations. This paper presents the first effort to design and implement a high speed 32-bit floating-point FPGA-based coprocessor for real-time SENSE reconstruction, using HLS frame work.METHODOLOGY
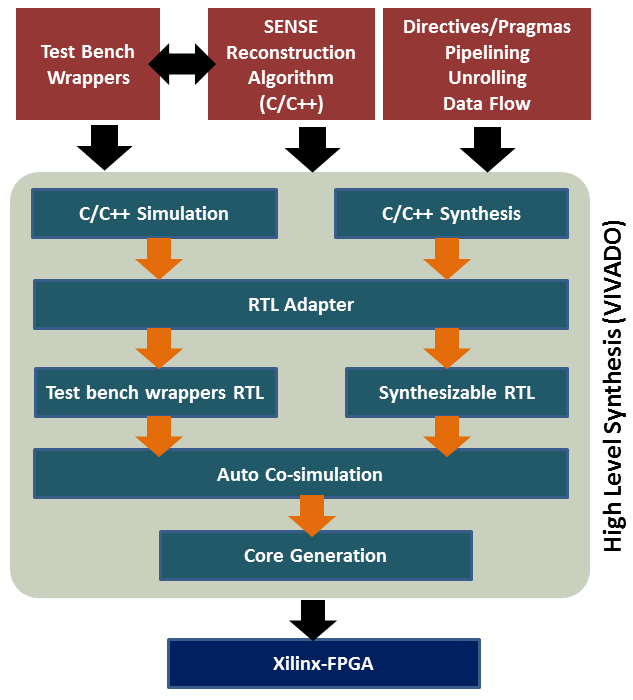
The proposed 32-bit floating-point FPGA-based coprocessor for SENSE reconstruction (32-co-SENSE) is designed and implemented using a contemporary tool named as vivado-HLS as shown in Figure 1. The development flow of the proposed coprocessor (Figure 1) is targeted for the Xilinx-FPGA with clock frequency of 400MHz where, vivado-HLS accepts synthesizable C++ implementation of SENSE algorithm as an input and performs advanced platform-based code transformations and synthesis optimizations (using directives/pragmas) to generate optimized synthesizable RTL. Furthermore, automatic co-simulations are performed using test bench wrappers to verify the correctness of the RTL output. Finally, the synthesizable RTL of the proposed co-processor is transformed into a complete FPGA implementation using vivado-design tools.
The proposed 32-co-SENSE iteratively performs complex matrix inversions for unfolding and combining the multi-channel aliased images and depositing the final composite image in the memory unit $$$M_{p}$$$ as shown in Figure 2. During each iteration, 32-co-SENSE reads multi-channel folded images and sensitivity encoding matrix from the pre-loaded memory units i.e. $$$M_{f}$$$ and $$$M_{s}$$$ respectively and subsequently performs least-squares i.e. $$$ρ=\left[\left(S^{H}\times{S}\right)^{-1}\times{S^{H}}\right]\times{I}$$$, on the set of elements from the encoding matrix $$$S\in\mathbb{C}^{N_{c}\times{A_{f}}}$$$ and set of folded pixels $$$I\in\mathbb{C}^{N_{c}\times{1}}$$$ for each receiver coil, to recover the actual values of pixels $$$ρ\in\mathbb{C}^{N_{c}\times{1}}$$$ in the solution image. The proposed architecture of the 32-co-SENSE is featured by single-precision parallelized complex rectangular matrix-inversion module as a part of the least-squares solution, consisting of four pipelined combinational units i.e. $$$MUL_{MM1}$$$, $$$INV$$$, $$$MUL_{MM2}$$$ and $$$MUL_{MV}$$$ as shown in Figure 2, where $$$MUL_{MM1}$$$ and $$$MUL_{MM2}$$$ perform complex matrix-matrix multiplication, $$$INV$$$ performs complex matrix-inversion and $$$MUL_{MV}$$$ performs complex matrix-vector multiplications. Each combinational unit uses dedicated DSP48 slices to support the floating-point operations for reconstruction accuracy, whereas, HLS design directives i.e. Pipelining and Loop-Unrolling are used to exploit the parallelism between each loop iteration of the SENSE algorithm.
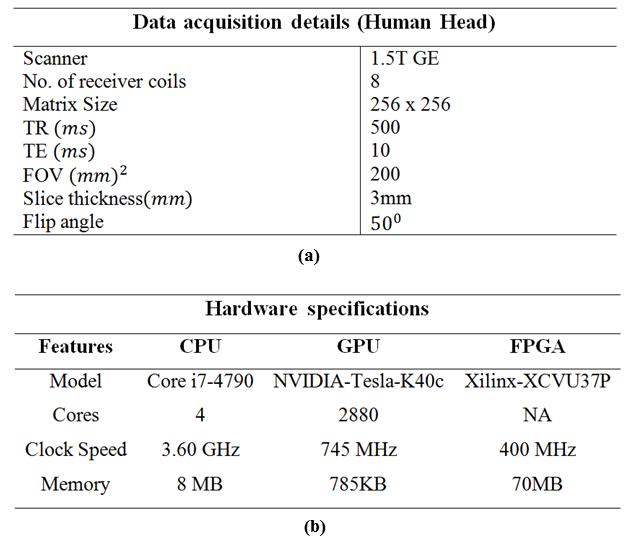
The performance of the 32-co-SENSE is compared with two hardware platforms (i.e. multicore-CPUs5 and GPUs3) using 8-channel in-vivo human head data set acquired on 1.5T scanner. The data acquisition details and hardware platform specifications used in our experiments are given in Table 1 and Table 2 respectively. For a comparison between the 32-co-SENSE and SENSE-reconstruction using CPU5 and GPU3, the computation time and reconstruction accuracy (in terms of SNR) of the reconstructed images is evaluated for acceleration factor $$$(A_{f})=2$$$.
RESULTS AND DISCUSSION
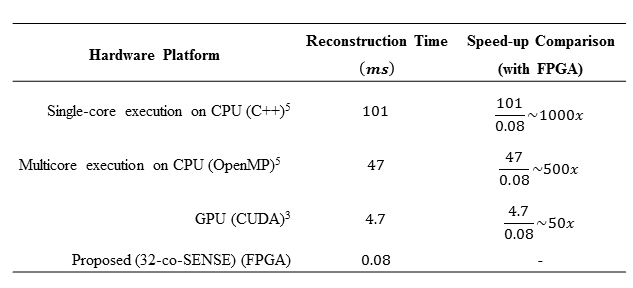
The reconstruction time of the proposed
32-co-SENSE is compared with SENSE reconstruction using multicore-CPU5
and GPUs3 as shown in Table 3. The results show that the 32-co-SENSE
significantly improves the reconstruction time up to a factor of $$$1000x$$$. The
reconstructed images of the 32-co-SENSE, multicore-CPUs and GPUs are shown in
Figure 3 for visual comparison. The results show that there is no significant
difference in the visual quality and SNR of the reconstructed images using the 32-co-SENSE reconstruction as
compared to the conventional CPU and GPU based reconstruction.CONCLUSION
This work presents the design and implementation of a new high performance 32-bit floating-point FPGA-based coprocessor for SENSE reconstruction using HLS. The results show that the combination of HLS design, debug, and analysis environment leverages optimizations to the proposed coprocessor for high speed SENSE reconstruction without compromising the image quality.Acknowledgements
No acknowledgement found.References
[1] Pruessmann, Klaas P., et al. Magnetic resonance in medicine 42(5): 952-962, 1999
[2] Ullah, Irfan, et al. Computers in biology and medicine 95: 1-12, 2018
[3] Shahzad, H., et al. Applied Magnetic Resonance 47(1):: 53-61, 2016
[4] Cong, Jason, et al. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 30(4): 473-491, (2011)
[5] Siddiqui, Muhammad Faisal, et al. Magnetic resonance imaging 44: 82-91, 2017
Figures
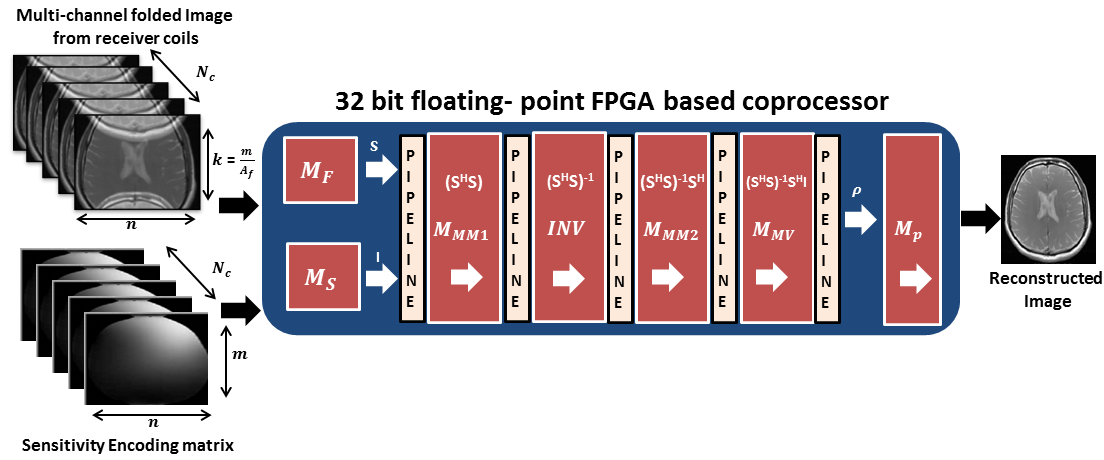
Architecture of the proposed 32-bit floating-point coprocessor for SENSE reconstruction (32-co-SENSE) .The proposed system receives uncombined multi-channel folded images and Sensitivity Encoding matrix, in memory models $$$M_{f}$$$ and $$$M_{s}$$$ respectively. Subsequently, four pipelined combinational units i.e. $$$MUL_{MM1}$$$, $$$INV$$$, $$$MUL_{MM2}$$$ and $$$MUL_{MV}$$$ solve least squares problem i.e. $$$ρ=\left[\left(S^{H}\times{S}\right)^{-1}\times{S^{H}}\right]\times{I}$$$ to recover the actual values of pixels in the solution image