1586
An generalized single MR image super resolution approach using combined super-resolution network and cycle-consistent adversarial networkBotian Xu1,2, Yaqiong Chai1,2, Kangning Zhang3, Natasha Lepore1,2, and John Wood1,2
1Department of Biomedical Engineering, University of Southern California, Los Angeles, CA, United States, 2Children's Hospital Los Angeles, Los Angeles, CA, United States, 3Department of Electrical and Computer Engineering, University of California, Davis, Davis, CA, United States
Synopsis
Traditional inception-based convolutional neural networks (CNN) are proved to be capable of tackling high resolution image restoration, yet they are poor at generalization due to the supervised learning procedure. We proposed a combination of CNN-based super resolution network and generative adversarial network, to make full use of the learning of high resolution from CNN, as well as to improve the generalization of the network, by preserving the original contrast of the sequence. The result shows that our proposed network could perform MR super resolution across sequences with higher quality than that from a single CNN network.
Introduction
MRI images in the clinic are often acquired at lower resolutions to shorten scanning time in high throughput settings, and simultaneously reduce patient movement artifacts, especially in pediatric cohorts1. However, high resolution images (HR) are required for these scans to be useful for imaging research. This problem may be remedied through the application of super-resolution methods on the low-resolution images. Current learning-based super-resolution approaches using inception-based fully convolutional neural networks (CNN) are generally supervised, which requires paired low and high-resolution images to train the network2. However, the latter are usually not available in clinical datasets. Additionally, paired supervision leads to weak generalization, meaning that the contrast of the specific MR sequence cannot be extended to prediction across modalities. Generative adversarial networks (GAN)3 have become increasingly popular in imaging research as a means to learn image features, and they perform well in image synthesis, yet they cannot generate high-resolution images4. Here, we proposed a weak-supervised super resolution (SR) approach, which we call generalization-enhanced SR network (GESR-net), using a combination of SRNet5 and cycle-consistent Net6. Our network not only keeps the high-resolution property from the SR-network, but also improves the generalization of the super resolution (SR) network by preserving the original contrast of the sequence.Method
Brain MR images acquired at 3T were randomly chosen from a publicly available dataset, the Human Connectome Project (HCP) S1200 dataset. Typical coronal slices of T1 and T2 weighted images from the same subject are exhibited in Figure 1, and these datasets were used as ground truth. We down-sampled both images by a factor of 5 in the axial direction to simulate clinical low-resolution images, as the input images of our proposed network. We then followed our proposed GESR-net method as illustrated in Figure 2. The architecture details and hyperparameters of SR-net and the data-consistent Net are illustrated in Figures 3 and 4, respectively. Note that SR-net only takes T1 images for training, and predicts a “high resolution” T2 from the downsampled T2. Because the training procedure of SR-net is not involved in any T2 image, the predicted high resolution T2 has a poor contrast. Therefore, the cycle-consistent net, which performs a contrast learning task, takes the poor contrast T2 and the real T2 to learn the contrast by adversarially transferring. In the SR-net, we use the mean square error (MSE) for the loss function of super resolution. For contrast learning, the loss is the combination of generative-adversarial loss and cycle-consistent loss. The network models were implemented in Python with TensorFlow and Keras. We evaluated the performance of the proposed method by comparing the recovered HR images with the original HR ones, employing the mean square error (MSE) and the peak signal-to-noise ratio (PSNR) as evaluation measures. We also used another image quality assessment, the structural similarity index (SSIM), which is more closely correlated with quality perception in the human visual system.Results and Discussion:
We tested our GESR method by training T1-weighted images and predicting T2-weighted images task. The third and fourth columns shows the prediction results of the SR network and those of the GESR network. It can be observed that the SR network yields images with severe blurring artifacts, while the proposed method best preserved edges and achieved better contrast between white and grey matter. Quantitative results on the images shown in Figure 1 are summarized in Table 1. Note that the proposed network yielded 11% higher PSNR and 4% higher SSIM in T2 image prediction, compared to SR-net only. The predicted T1 images by GESR-net has the similar image quality with that by SR-net, meaning that our proposed method did not hamper the high-resolution property from the previous network. We tested our GESR method in a training T1-weighted images and predicting T2-weighted images task. The experiments show that our method over performed traditional SR methods in generalization of cross modalities prediction. However, the super resolution module in our proposed network still requires paired images for supervised learning For the future, GESR net can achieve fully unsupervised learning if the super resolution module were improved to unsupervised method.Acknowledgements
No acknowledgement found.References
1. Fezoulidis I V. T2 FLAIR artifacts at 3-T brain magnetic resonance imaging. J Clin Imaging. 2013;38(2):85-90. 2. Yang W, Zhang X, Tian Y, Wang W, Xue J. Deep Learning for Single Image Super-Resolution : A Brief Review. arXiv preprint 3. Goodfellow IJ, Pouget-abadie J, Mirza M, Xu B, Warde-farley D. Generative Adversarial Nets. In Advances in neural information processing systems (pp. 2672-2680) 4. Huang H, Yu PS, Wang C. An Introduction to Image Synthesis with Generative Adversarial Nets. NIPS 2018:1-17. 5. Iqbal Z, Nguyen D, Hangel G, Bogner W, Jiang S. Super-Resolution 1H Magnetic Resonance Spectroscopic Imaging utilizing Deep Learning. arXiv preprint arXiv:1802.07909(2018). 6. Zhu JY, Park T, Isola P, Efros AA. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. Proc IEEE Int Conf Comput Vis. 2017;2017-October:2242-2251.Figures
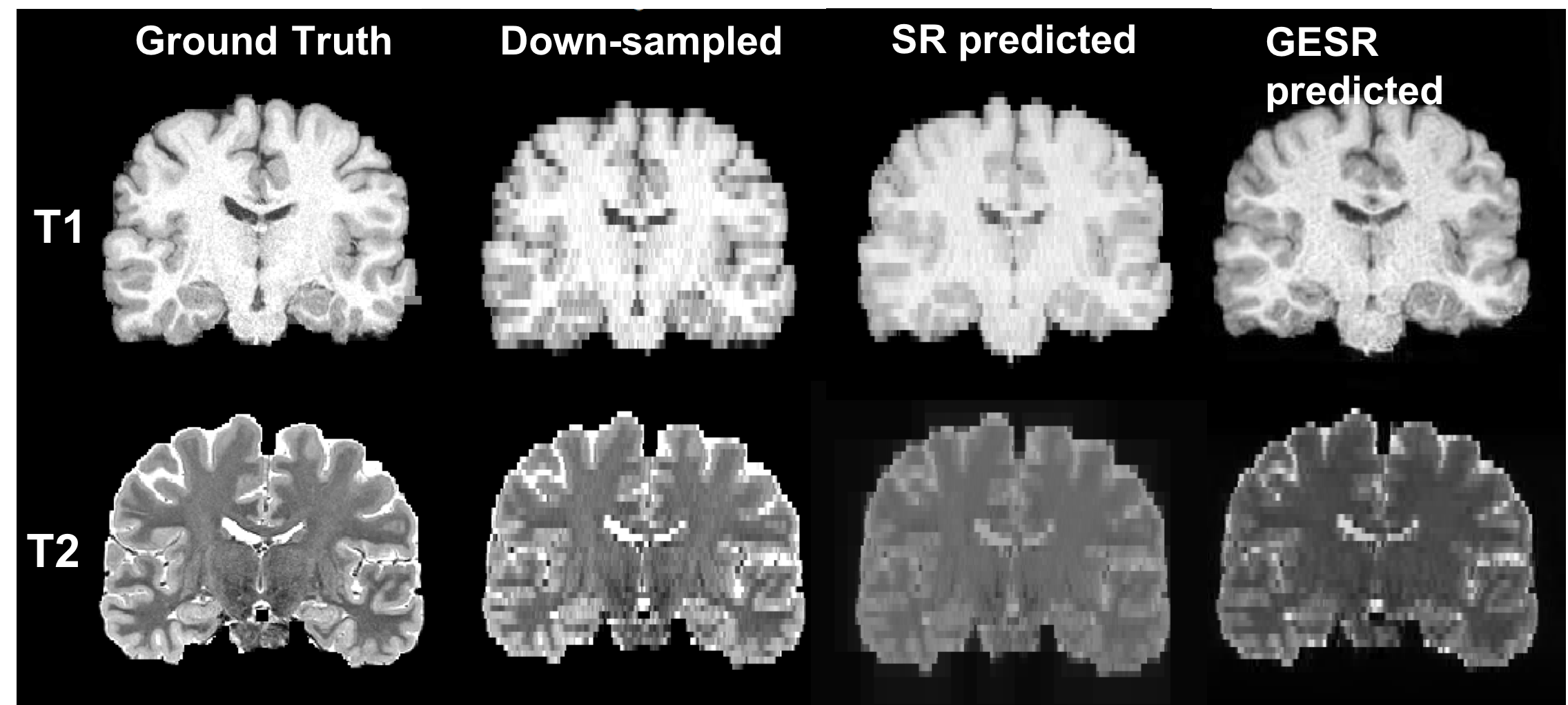
Coronal slices of T1 and T2 images.
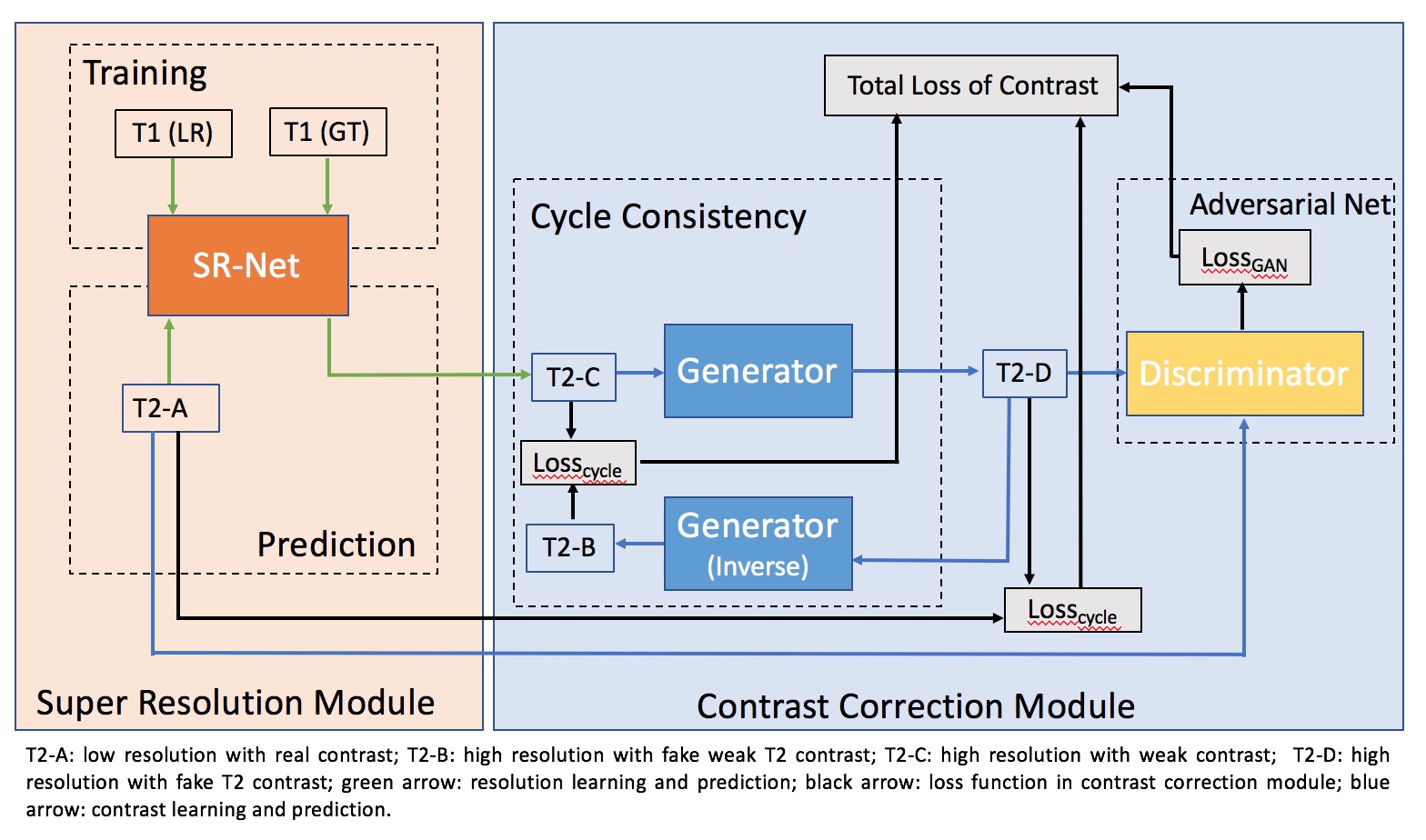
The SR-net is trained only by T1
images, and takes a downsampled T2
image (T2-A) as the input to predict a high resolution T2, which will be the
input image (T2-C) of the contrast correction module. Thereafter, T2-A and T2-C
are used for contrast learning. The generator generates T2-D with faked T2
contrast based on the real T2 contrast from T2-A. Additionally, an inversed
generator, having
the
same structure with the generator, outputs T2-B to calculate cycle loss with
T2-C. The discriminator calculates the GAN loss based on the real T2 contrast
and the fake T2 contrast.
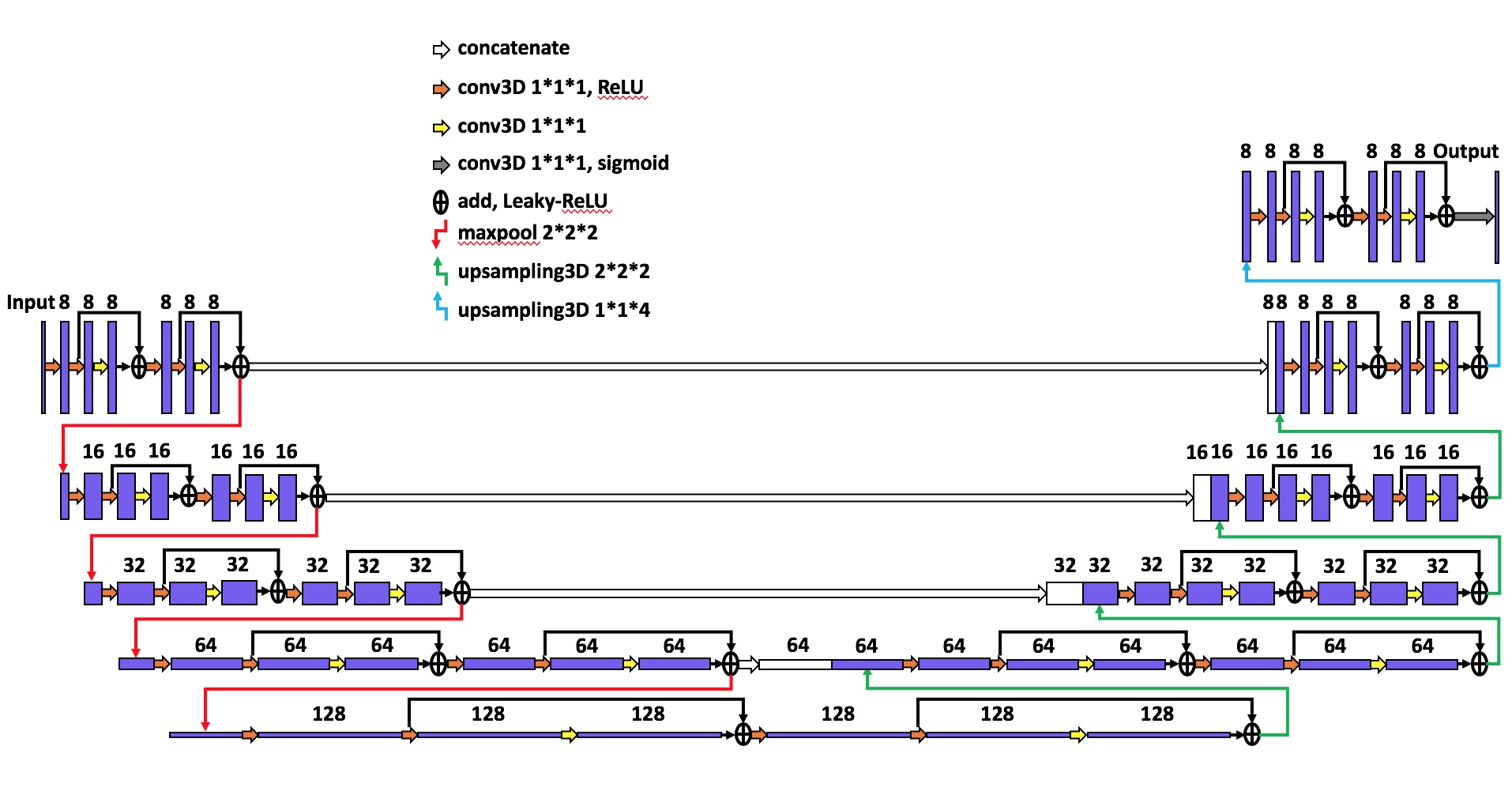
The architecture and hyperparameters of
the SR-net. The numbers of channels for each layer are shown above the layers.
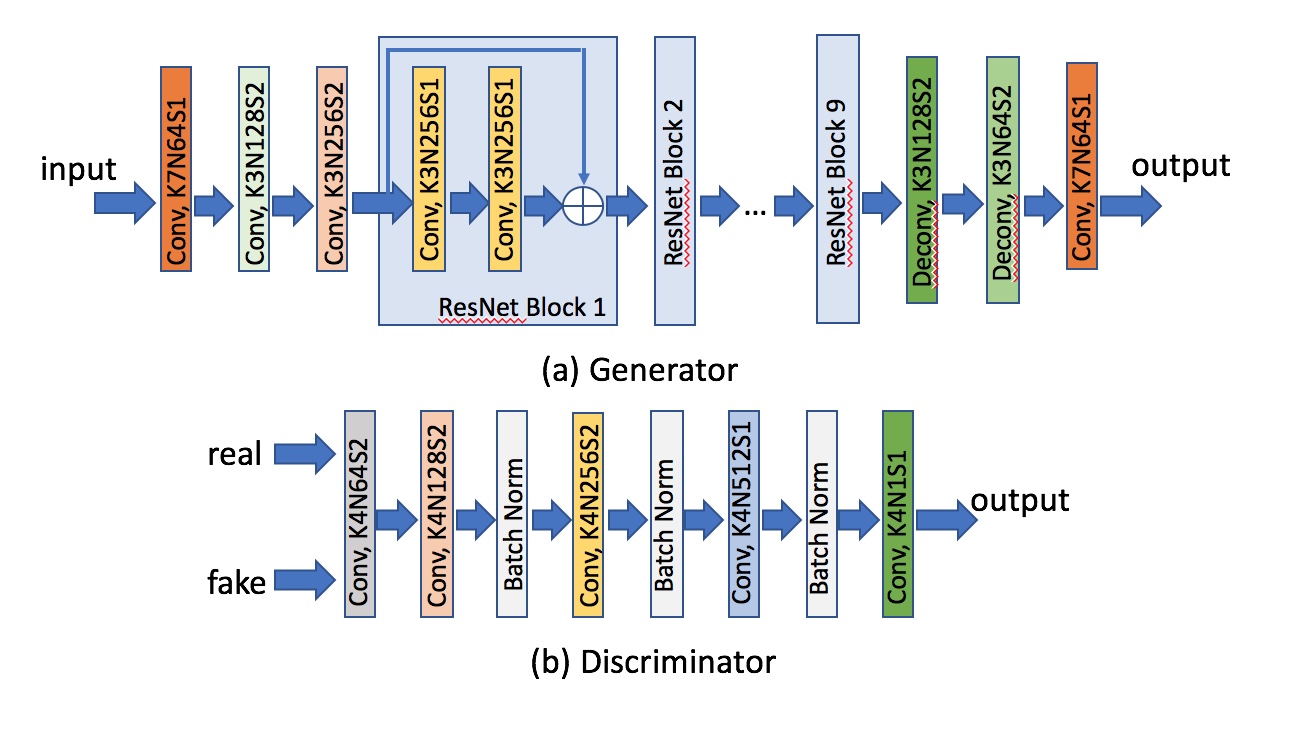
The architectures and hyperparameters of
the generator and the discriminator in cycle-consistent GAN. Conv:
convolutional layer; Deconv:
deconvolutional layer;
Batch Norm: batch normalization; for each
conv and deconv
layer, the hyperparameters are indicated as K: kernel size; N: the number of
channels; S: strike size.

Image quality evaultions