1309
Transfer Learning in Hip MRI Segmentation: Geometry Is More Important Than Contrast1Radiology and Biomedical Imaging, University of California, San Francsico, San Francisco, CA, United States, 2Bioengineering, University of California, Berkeley, Berkeley, CA, United States, 3Center for Digital Health Innovation, University of California, San Francsico, San Francisco, CA, United States
Synopsis
Transfer learning for medical image segmentation tasks is a promising technique that has the potential to overcome the challenges posed by limited training data. In this study we investigate the contribution of geometrically-similar and contrast-similar features for transfer learning to a hip MR segmentation task. We show pretraining with a geometrically similar task leads to more rapid convergence, can stabilize segmentation accuracy as datasets become reduced in size, and leads to more reliable biomarker extraction.
Introduction
Advances in MR acquisition have made it possible to collect large volumes of imaging data during patient visits, enabling the characterization of diseases on a population level. However, manually or semi-automatically extracting biomarkers by dense segmentations and placement of ROIs is costly and rate-limiting. With large annotated datasets, deep learning algorithms are achieving state of the art performance in segmentation tasks1, but there is a growing need to understand how to leverage these methods with smaller datasets. Transfer learning has the potential to overcome challenges from limited training data2. This study aims to investigate the contribution of geometrically-similar features and contrast-similar features for transfer learning in a hip MRI semantic segmentation task. Specifically, quantifying the effect of geometry and contrast transfer learning on (1) network convergence speed, (2) segmentation accuracy, and (3) biomarker extraction accuracy as the training dataset shrinks from 78 to 5 volumes.Methods
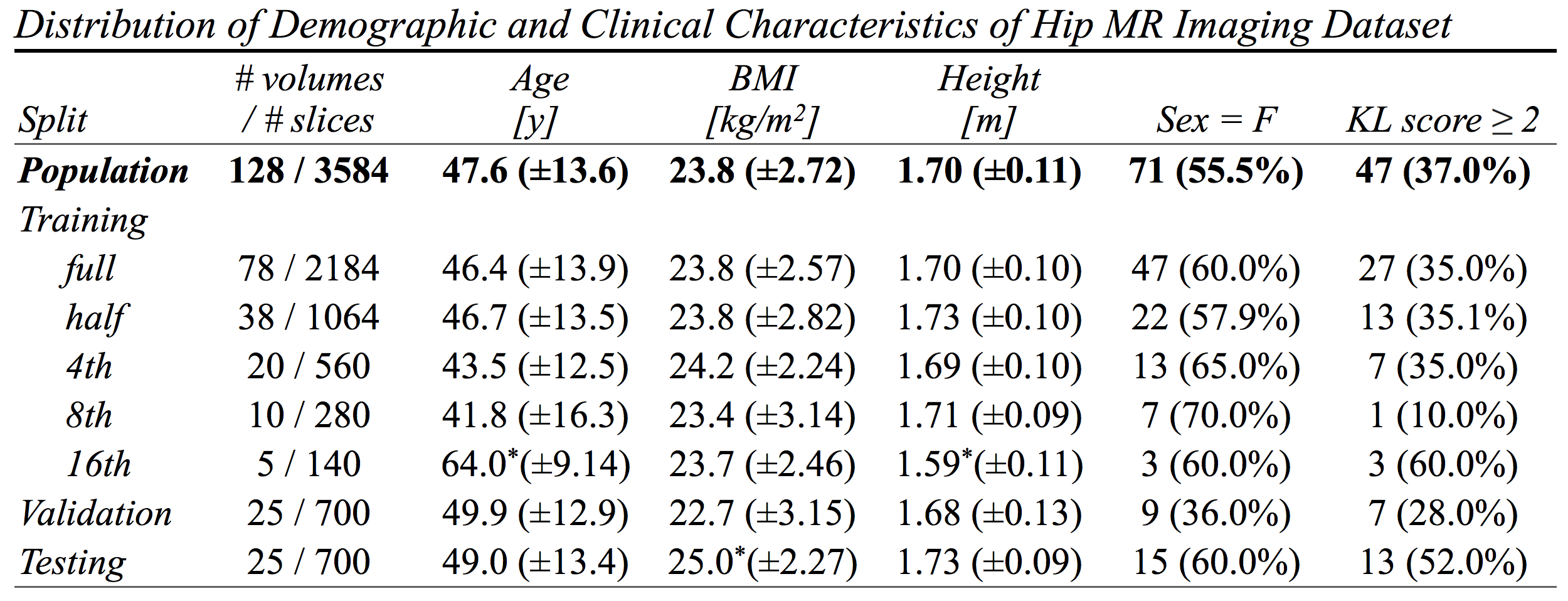
128 hip MR volumes (46 patients) were acquired as part of a longitudinal hip osteoarthritis study Figure1. Images were acquired on a 3T scanner (GEMR750, GE Healthcare, Waukesha,WI) using an 8-channel receive-only cardiac coil. Imaging included a 13:47 minute T1ρ/T2 sequence (MAPSS)3: FOV=14cm, BW=62.5kHz, voxel_size=0.5x0.5x4mm, TSL=0/15/35/45ms, TE=0/10.4/20.8/41.7ms. Ground truth (GT) segmentations of acetabular cartilage, femoral cartilage, and proximal femur were performed semi-automatically on TSL=0 and quality controlled using a spline-based in-house Matlab (Mathworks, Natick, MA) package.
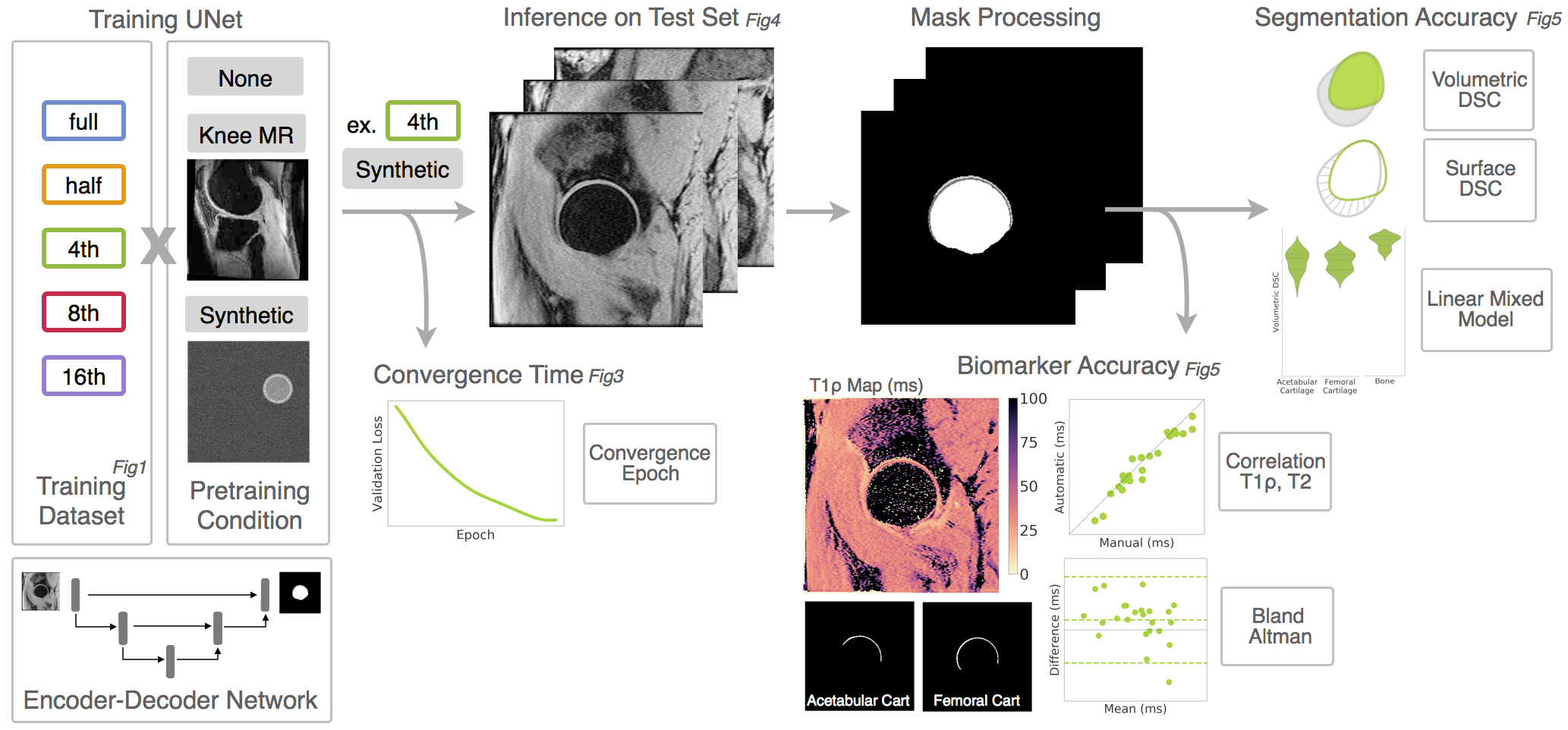
Training/validation/testing split was 60/20/20. Training data was halved four times, creating 5 training datasets. 3 transfer learning approaches for weight initialization were compared: Xavier initialization (no pretraining), contrast-similar segmentation task (knee MR pretraining), and geometrically-similar segmentation task (synthetic pretraining) Figure2.Contrast-similar task: segmentation of femoral and tibial cartilage on a MAPSS sequence of the knee (dataset4). Geometrically-similar task: synthetic data created with circles and two concentric rings, mimicking the bone cartilage interface at the femoral head.
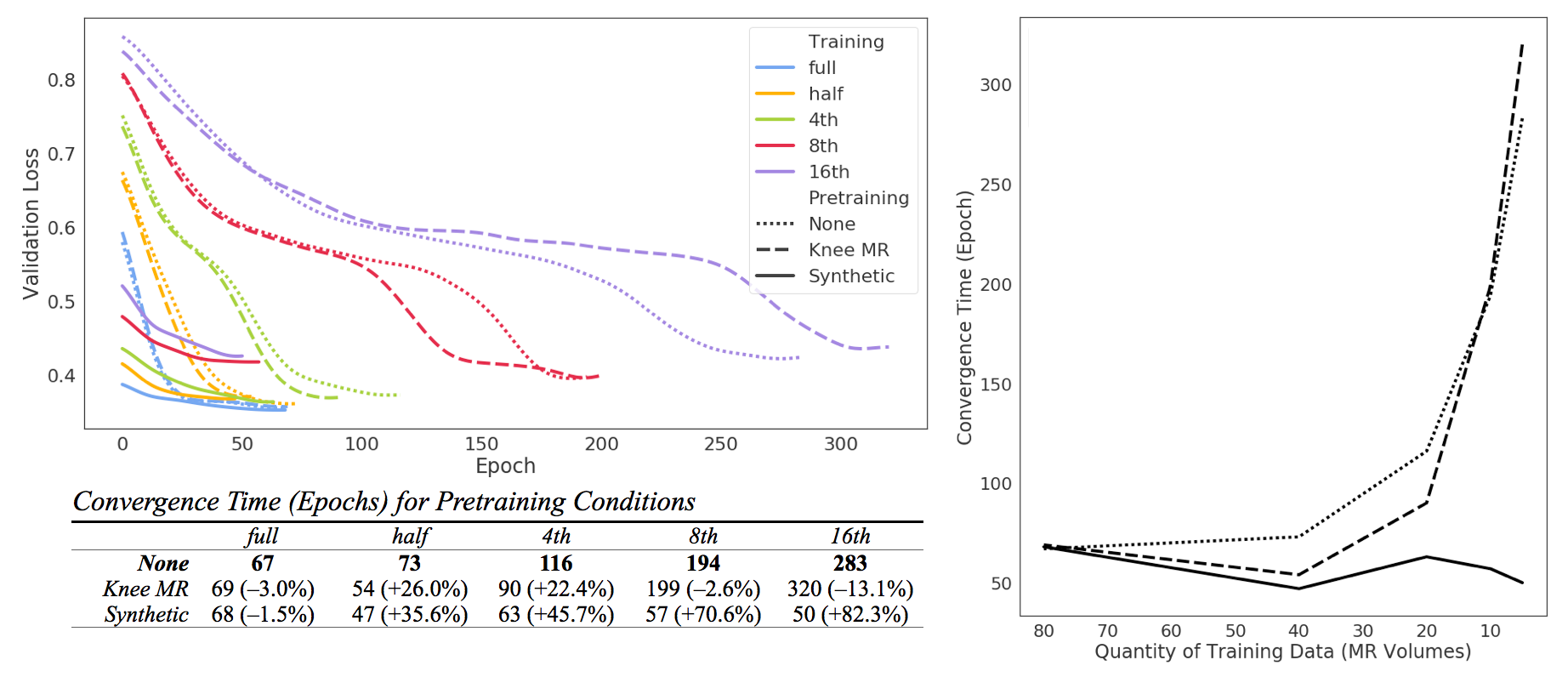
A 2D UNet5 architecture was trained to segment 4 classes (background, bone, femoral cartilage, acetabular cartilage) on 256x256 sagittal slices. Slices augmented by random translations (±15), rotations(±25˚), masks interpolated using nearest neighbor. UNet with ReLu activations, batch normalization, soft Dice Similarity Coefficient loss6 (mean multi-class DSC), batch size 16, learning rate 0.001, Adam optimizer, no dropout. End-to-end training in PyTorch, run on 4xTeslaV100 with early stopping. Checkpoint meeting convergence criteria (first epoch where validation loss> 5th percentile of losses) used for inference Figure3.
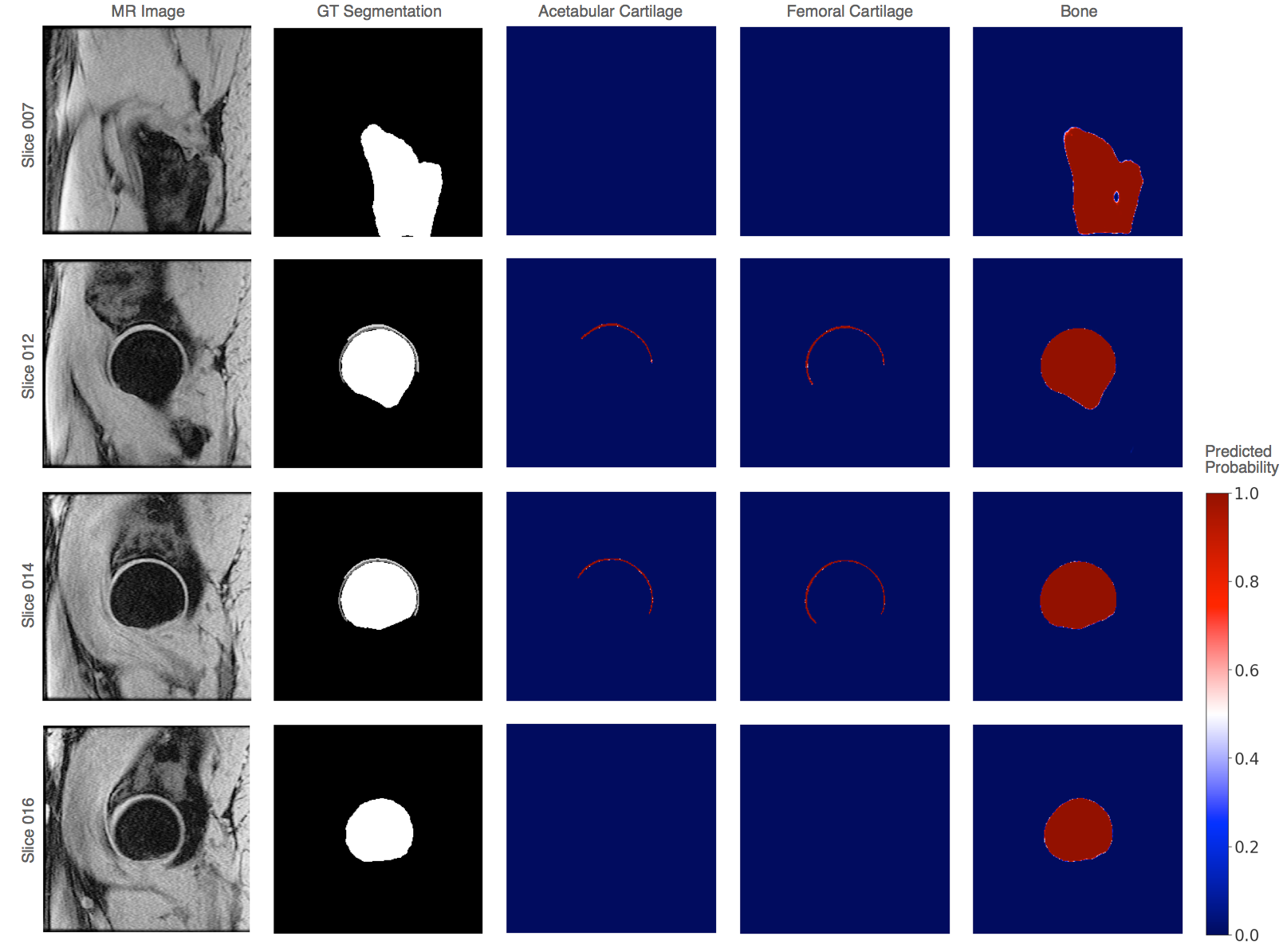
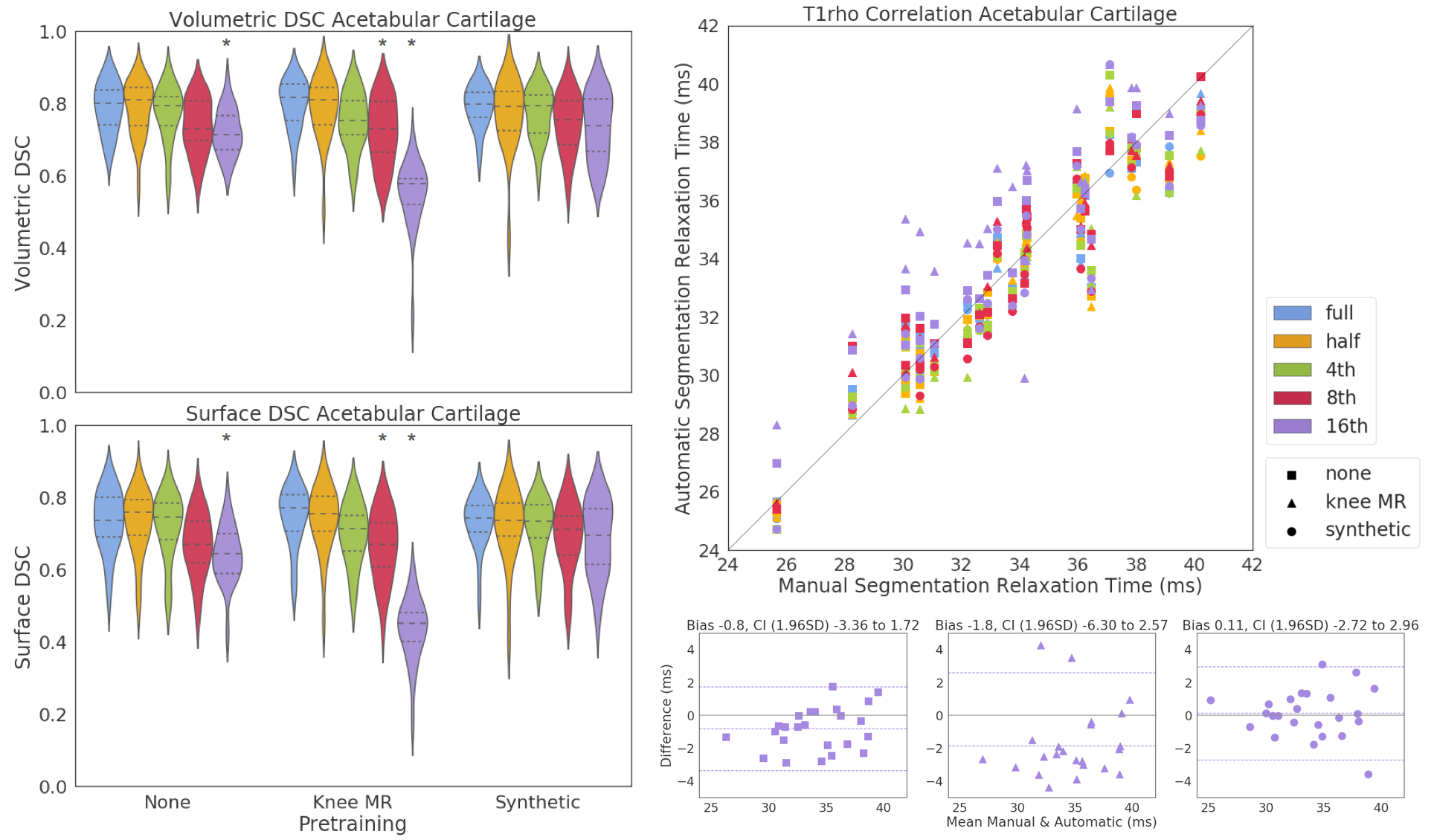
Testing dataset run through inference of 15 trained networks. Inferred slices stacked as a 3D mask, processed with binary hole filling and largest connected component per-class, and compared to GT. Representative segmentations for full training dataset in Figure4. Volumetric DSC calculated as 2*(infer∩GT)/(infer+GT). Surface DSC calculated as fraction of surface distances that are within tolerance 0.5mm. DSC scores compared using (1) t-tests and (2) a linear mixed model with pretraining condition and dataset size as fixed effects and subject specific random effects to account for multiple timepoints. Inferred cartilage mask volumes overlaid onto the T1ρ,T2 maps and assessed for agreement via Spearman’s correlation and Bland-Altman plots.
Results
For full dataset size, all pretraining methods converged in similar time. GS (synthetic) pretraining led to faster convergence at dataset splits half/4th/8th/16th, with convergence speedup more pronounced the smaller the dataset (82.3% improvement at 16th) Figure3. CS (knee MR) pretraining showed marginal improvements in speed at dataset split half/4th but showed decreases in speed at 16th.
Visual analysis of segmentation logits shows high confidence in cartilage and bone segmentation near the femoral head with more uncertainty in the lateral shaft of the proximal femur and on book-end slices with partial voluming.
There was no significant difference in volumetric or surface DSC with dataset shrinkage in synthetic pretraining condition, while knee MR pretraining significantly worsened DSC at smaller datasets. Similar trends seen femoral cartilage and bone. Surface DSC tended to be more sensitive to errors in segmentation. Overall, manual and automatically extracted biomarkers were highly linearly correlated (r >0.95) with networks trained on smaller datasets biased towards overestimating relaxation times Figure5. Subject specific random effects explained the least amount of variability in the DSC scores.
Conclusion
In this hip MR segmentation task, pretraining can benefit or hurt performance depending on dataset size and pretraining condition. Geometrically similar pretraining (1) accelerated convergence, (2&3) stabilized segmentation accuracy and biomarker extraction performance throughout dataset shrinkage. These results suggest that transfer learning with geometrically similar features could overcome limited dataset size, with the added benefit of fast convergence freeing up computational resources to optimize network architecture and hyperparameters. Future work will focus on creating synthetic datasets with greater geometrical-similarity.Acknowledgements
Funding sources: NIH ARP50AR060752, NIH AR R01046905, NIH K99AR070902References
1Chen, Liang-Chieh, et al. "Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs." IEEE transactions on pattern analysis and machine intelligence 40.4 (2018): 834-848.
2Hoo-Chang, Shin, et al. "Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning." IEEE transactions on medical imaging 35.5 (2016): 1285.
3Li, Xiaojuan, et al. "Simultaneous acquisition of T1ρ and T2 quantification in knee cartilage: repeatability and diurnal variation." Journal of Magnetic Resonance Imaging 39.5 (2014): 1287-1293.
4Norman, Berk, Valentina Pedoia, and Sharmila Majumdar. "Use of 2D U-Net Convolutional Neural Networks for Automated Cartilage and Meniscus Segmentation of Knee MR Imaging Data to Determine Relaxometry and Morphometry." Radiology (2018): 172322.
5Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015.
6Milletari, Fausto, Nassir Navab, and Seyed-Ahmad Ahmadi. "V-net: Fully convolutional neural networks for volumetric medical image segmentation." 3D Vision (3DV), 2016 Fourth International Conference on. IEEE, 2016.
Figures