1091
Contrast-free MRI Contrast Enhancement with Deep Attention Generative Adversarial Network1Tsinghua University, Beijing, China, 2Stanford University, Stanford, CA, United States, 3Subtle Medical Inc., Menlo Park, CA, United States, 4Grenoble Institute of Neurosciences, Grenoble, France
Synopsis
While gadolinium-based contrast agents (GBCAs) have been dispensable for magnetic resonance imaging in clinic practice, recently there are rising concerns about the safety of GBCAs. In previous studies, we tested the feasibility of predicting contrast agents from pre-contrast images via deep convolutional neural networks. In this study, we further improved the results with deep attention generative adversarial network. The image similarity metrics show that the model can synthesize post-contrast T1w images with superior image quality and great resemblance to the ground truth images. Restoration of contrast uptake is clearly noted on the synthesized images even in small vessels and lesions.
Introduction
While gadolinium-based contrast agents (GBCAs) have been dispensable for magnetic resonance imaging in clinic practice, recently there are rising concerns about the safety of GBCAs. In order to reduce the side effects of GBCAs, the dosage of GBCA should be as low as possible, especially for patients who require repeated contrast-enhanced MRI scans. In previous studies1,2, we tested the feasibility of predicting contrast agents from pre-contrast images via deep convolutional neural networks (CNNs). In this study, we further improved the results with deep attention generative adversarial network (GAN).Method
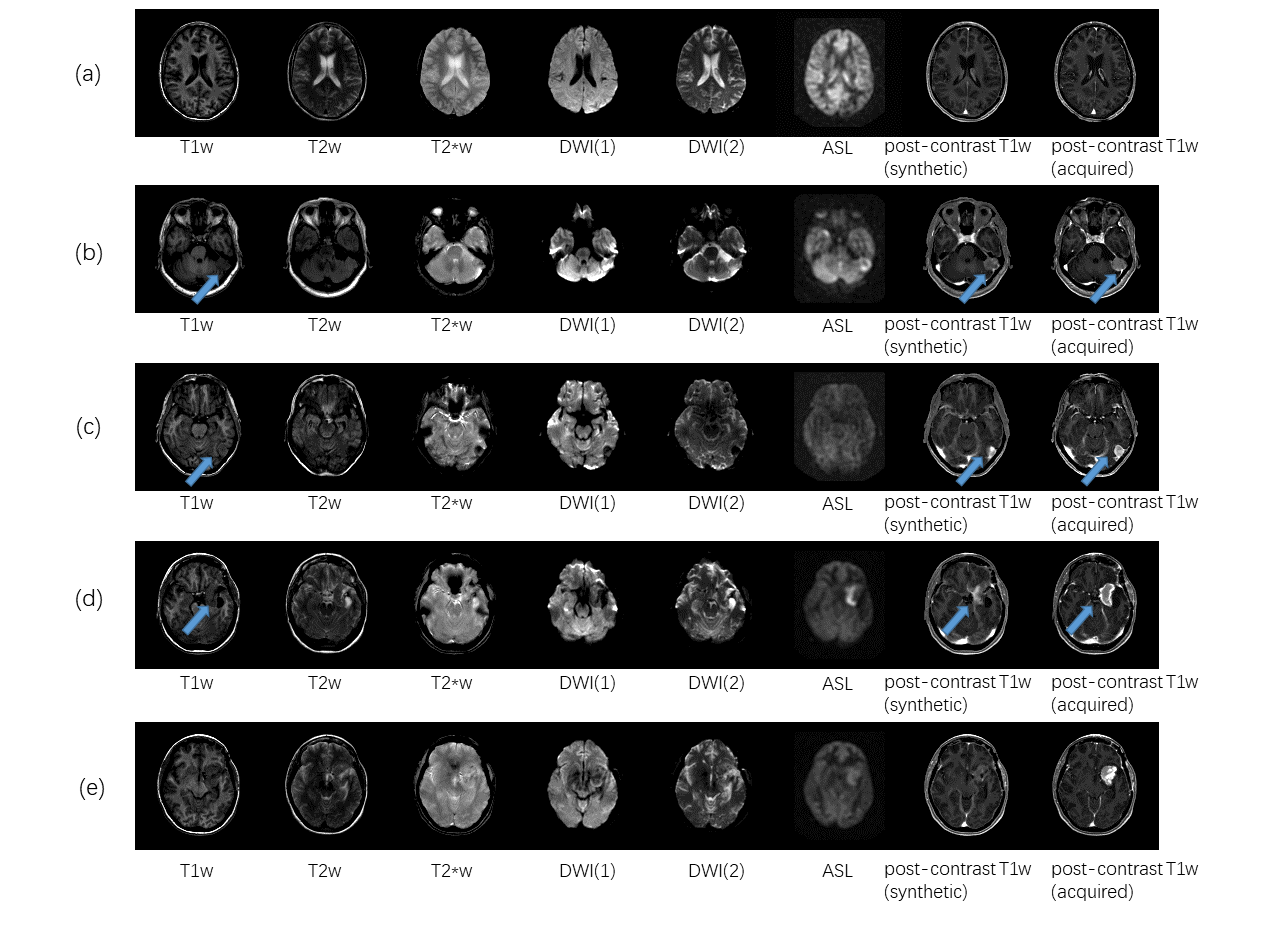
① Dataset and preprocessing: MR acquisitions were performed at 3T (GE Healthcare Systems, Waukesha, WI) with an 8-channel GE head coil. The MR protocol included 6 sequences (3D IR-prepped FSPGR T1w, T2w, FLAIR T2w, diffusion-weighted imaging (DWI) with 2 b-values (b=0, b=1000), T2*w and 3D ASL) acquired before injection of 0.1 mmol/kg gadobenate dimeglumine (Multihance; Bracco) and one sequence (3D IR-prepped FSPGR T1w) acquired after injection. The acquired data was co-registered to the MNI template with 2mm isotropic spatial resolution. 404 patients with different clinical indications and brain abnormalities were scanned. 323 patients chosen randomly in the cohort were used for training and the rest were used for testing. The top and bottom five slices in each case were discarded due to low signal-to-noise ratio (SNR). Figure 1 shows an example of the data that includes the 6 pre-contrast images used as input and the T1w image acquired after injection as output.
② Network architecture: The network architecture is shown in Figure 2, which follows standard conditional GAN framework with one generator and one discriminator, where the generator takes 2.5D pre-contrast images with 6 contrasts (T1w, T2w, T2*w, DWI (1), DWI (2) and ASL, 5 slices each) as input and predicts single T1w image acquired after injection. The basic component of the generator is the attention U-Net block3, which automatically learns to focus on the most important structure for contrast enhancement prediction. We designed the generator with a similar idea as “boosting” in machine learning, that a second block learns to compensate the output of the first block and they together form a more powerful generator to produce the final output, for accurate prediction of global contrast changes as well as local details. For discriminator, a 6-layer convolutional network was used.
③ Loss function: In addition to L1 loss between the synthesized image and target image, we used adversarial loss4 Ladv and perceptual loss5 Lpercep from the discriminator to encourage more realistic outputs. The overall loss function is defined as L=L1 + λ1 Ladv + λ2 Lpercep, where we empirically chose λ1 = 0.1 and λ2=0.5.
Results
We evaluated the performance of the proposed method on the test set with peak signal-to-noise ration (PSNR) and structural similarity (SSIM) index. The generated images have PSNR of 27.5 ± 5.6 and SSIM of 0.939 ± 0.031 compared to acquired post-contrast T1w images, which is significantly higher than pre-contrast T1w images (PSNR of 19.5 ± 6.5 and SSIM of 0.836 ± 0.055) as well as results of the previous method1 (PSNR of 25.7 ± 6.5 and SSIM of 0.927 ± 0.042). In addition to higher similarity metrics, the proposed method is able to enhance more detailed structure compared to the previous method (see Figure 3). Figure 4 shows several examples from the test set. Restoration of the contrast uptake is clearly noted on the synthesized post-contrast images even in small vessels (Figure 4 (a)) and lesions (Figure 4 (b) and (c)), although in some cases the enhancement is less conspicuous (Figure 4 (d)). Figure 4 (e) is an example where the contrast uptake is missed in the synthesized post-contrast images.Discussion and Conclusion
In this study, we proposed a 2.5D attention generative adversarial network to predict contrast agent enhancement from multi-contrast non-contrast-enhanced images. The network was evaluated on a dataset of 404 patients with various ages, genders, and clinical indications. The image similarity metrics show that the model is able to synthesize post-contrast T1w images with superior image quality and great resemblance to the ground truth images. In addition, the model can successfully predict some enhancing lesions that are completely not shown in the pre-contrast images. However, the model still fails to predict some contrast uptakes which may due to lack of similar cases in the training set. With more training cases and further validation, this approach could have great clinical value especially for patients who cannot receive contrast agent injection.Acknowledgements
No acknowledgement found.References
1. Christen, T., Gong, E., Guo, J., Moseley M., &Zaharchuk G. (2018). Predicting Contrast Agent Enhancement with Deep Convolution Networks. ISMRM 2018 Proceedings.
2. Gong, E., Pauly, J. M., Wintermark, M., & Zaharchuk, G. (2018). Deep learning enables reduced gadolinium dose for contrast‐enhanced brain MRI. Journal of Magnetic Resonance Imaging.
3. Oktay, O., Schlemper, J., Folgoc, L. L., Lee, M., Heinrich, M., Misawa, K., ... & Glocker, B. (2018). Attention U-Net: Learning Where to Look for the Pancreas. arXiv preprint arXiv:1804.03999.
4. Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017). Image-to-image translation with conditional adversarial networks. arXiv preprint arXiv:1611.07004.
5. Johnson, J., Alahi, A., & Fei-Fei, L. (2016, October). Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision (pp. 694-711). Springer, Cham.
Figures