1041
OneforAll: Improving the Quality of Multi-contrast Synthesized MRI Using a Multi-Task Generative Model1Biomedical Engineering, Tsinghua University, Beijing, China, 2Electrical Engineering, Stanford University, Stanford, CA, United States, 3Subtle Medical, Menlo Park, CA, United States, 4Global Applied Science Laboratory, GE Healthcare, Menlo Park, CA, United States, 5Radiology, Stanford University, Stanford, CA, United States
Synopsis
To improve the quality and efficiency of multi-contrast MR neuroimaging, a new Multi-Task Generative Adversarial Network (GAN) is proposed to synthesize multiple contrasts using a uniformed network. The cohort of 104 subjects consisting of both healthy and pathological cases is used for training and evaluation. For both the subjective and non-subjective evaluation, the proposed method achieved improved diagnostic quality compared with state-of-the-art synthetic MRI image reconstruction methods based on model-fitting and also previously shown deep learning methods.
Introduction
Synthesized multi-contrast MR provides a faster and unified scanning process for clinical use. Using the saturation recovery multi-echo sequence, B1, PD, T1, and T2 maps are automatically computed, and images with multiple contrast weightings are automatically generated on the MR console using the synthetic MR based method, MAGiC.1,2 However, the traditional model-fitting methods can introduce some undesirable artifacts.2,3 Recently, reconstruction methods based on deep learning have shown the potential to correct the deficiencies of traditional methods.4,5
In this work, we further improve the data-driven contrast-synthesis by proposing a multi-task network which generates different contrasts more accurately using only one set of weights. Compared to previous networks that mapped a single contrast, we demonstrate this model utilizes the correlation between contrasts and reaches a mutual correction effect. To further promote and validate the performance of DL-based synthesized MRI, larger datasets with both healthy and pathological cases were acquired and applied in training and evaluation.
Methods
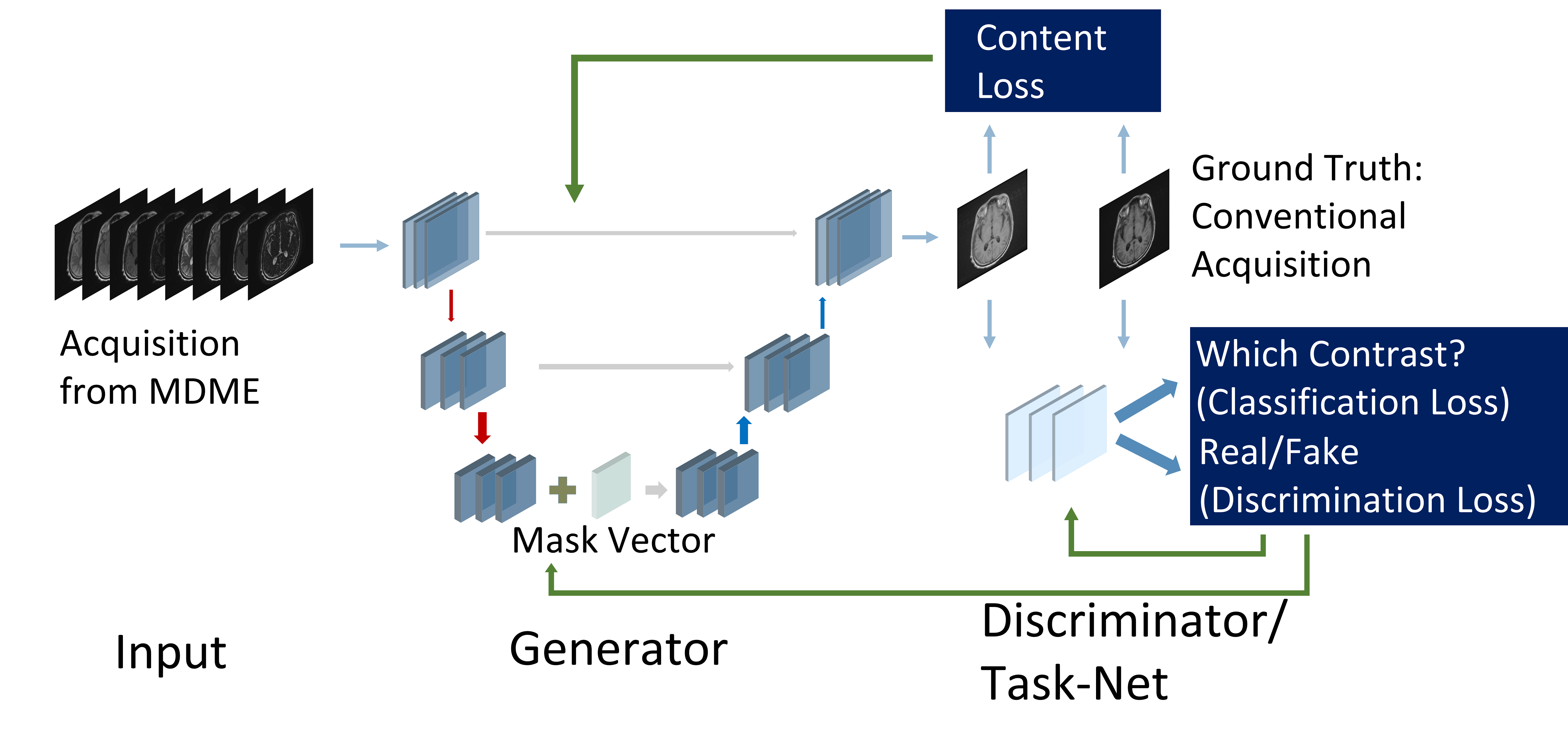
Network Structure: A Multi-Task Generative Adversarial Network (GAN) is proposed to generate different contrasts in one unified network [Fig.1]. The backbone of the Generator is based on the encoder-decoder structure with multi-view direct connection. Additional label (contrast) information is introduced to inform the generator which contrast to synthesize. The backbone of the discriminator is a multi-layer CNN with two separate predictional output nets. The first output net acts as the traditional discriminator and predicts whether the image is real (the ground truth) or fake (the generated). The second net is the proposed Task-Net, which predicts which contrast the image belongs to.
Loss Function: The loss function consists of three components. The first part is the content loss, which measures the distance between the generated image and ground truth (conventional MR images).
$$\underset{g}{min}E_{x,y,c}[\|G(x,c)-y\|_{1}]$$
$$$x$$$ is the input, $$$y$$$ is ground truth, and $$$c$$$ is the contrast (label) information.
The second part is the adversarial loss, which encourage sharper and more visually familiar images.
$$\underset{d}{min}E_{x}[D_{dis}(G(x))^{2}]+E_{y}[(D_{dis}(y)-1)^{2}]$$
$$\underset{g}{min}E_{x}[(1-D_{dis}(G(x)))^{2}]$$
The third part is the classification loss, which ensures the images have the desired contrast. The Task-Net is designed to evaluate which contrasts the generated image belongs to, with a cross-entropy loss function to regularize the generator, to restore accurate details and contrasts as the reference contrast-weighted MRI.
$$\underset{t}{min}E_{y,c'}[-log(c'|D_{cls}(y))]$$
$$\underset{g}{min}E_{x,c}[-log(c|D_{cls}(G(x,c)))]$$
Dataset: Of 104 datasets previously acquired at multiple sites,3 including the Multi-Dynamic Multi-Echo (MDME) sequence as source domain and traditional 2D FSE (T1w, T2w, T1-FLAIR, T2-FLAIR, PDw, and STIR) as ground truth, we used 83 datasets for training and 21 for testing, 2400 image pairs in total. Results generated by the MAGiC method are also used for comparison.
Results
Both image metrics and examples of different reconstructed methods are shown [Fig. 2-4]. Compared with the traditional model-fitting method (MAGiC), the proposed DL-based method introduces significantly fewer reconstruction artifacts. Compared with separately trained models, the multi-task GAN results in superior performance with a 6-times smaller model size. The generalization ability of the method is evaluated by being trained on only healthy cases and tested on pathological cases [Fig. 5].Discussion
Compared to the traditional pixel-wise fitting methods, the deep learning approach calculates intensity using information from a large-scale receptive field, rather than just local information employed in the least-square regression. The global information helps to prevent some errors and artifacts arising from motion or mis-registration, and make the output more stable against the singularity brought about by the acquisition imperfection. The risk of this task-setting is minimized because information of different contrast is inherently stored in the MDME sequence, described by the relaxometry function.
The improvement of the performance of over the previous single-task networks can be explained through different perspectives. First, it achieves a cross-correction effect between different contrasts. Using multi-task formulation, 6 conventional MR contrasts were used to train one generator. The deficiency in some destination contrasts would exert less influence on the encoder, with other contrasts’ correction. Secondly, the over-fitting problem is greatly alleviated through enlarging the training set six times. Third, the classifier learned the features between different contrasts by being trained on the conventional MR images, ensuring that the generated images match features with the conventional acquisition.
For further study, a larger dataset, a task-specific network, and a reader study could be explored.
Conclusion
This work formulated and validated a novel MR synthesis approach based on deep learning and improved design of GAN. The method successfully learns the joint probability distribution between Multi-Dynamic Multi-Echo imaging and conventional 2D brain imaging. It avoids the reconstruction artifacts in previous over-simplified models, and leads to more accurate and efficient synthesized multi-contrast MRI reconstruction.Acknowledgements
No acknowledgement found.References
1. Riederer SJ, Suddarth SA, Bobman SA, et, al. Automated MR image synthesis: feasibility studies. Radiology. 1984.
2. Hagiwara A, Warntjes M, Hori M, et, al. SyMRI of the brain: rapid quantification of relaxation rates and proton density, with synthetic MRI, automatic brain segmentation, and myelin measurement. Investigative radiology. 2017.
3. Tanenbaum LN, Tsiouris AJ, Johnson AN, et, al. Synthetic MRI for clinical neuroimaging: results of the Magnetic Resonance Image Compilation (MAGiC) prospective, multicenter, multireader trial. AJNR. 2017.
4. Gong E, Banerjee S, Pauly J, Zaharchuk G. Improved synthetic MRI from multi-echo MRI using deep learning. In 26th Annual Meeting of the ISMRM. 2018.
5. Liu F, McMillan A. MR image synthesis using a deep learning based data-driven approach. In 26th Annual Meeting of the ISMRM. 2018.
Figures