0880
3D Convolutional Neural Network with Contrast-enhanced MR for Microvascular invasion prediction of hepatocellular carcinoma1School of Medical Information Engineering, Guangzhou University of Chinese Medicine, Guangzhou, China, 2Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China, 3Department of Radiology, Guangdong General Hospital, Guangzhou, China
Synopsis
Microvascular invasion (MVI) of Hepatocellular carcinoma (HCC) is a crucial histopathologic prognostic factor leading to recurrence after liver transplantation or hepatectomy, and preoperative prediction of MVI is significant in clinical practice. In this work, we propose a deep learning framework based on 3D Convolutional Neural Network (CNN) to extract discriminative information from HCCs in Contrast-enhanced MR images for MVI prediction. Experimental results demonstrated that the proposed deep learning framework could make full use of the spatial and temporal information of HCCs from Contrast-enhanced MR for MVI prediction, outperforming the radiomics based approach and the method of 3D deep feature concatenation.
Introduction
Preoperative Microvascular invasion (MVI) prediction of hepatocellular carcinoma (HCC) has been shown to be helpful for patient management and deciding treatment strategy before hepatic resection or liver transplantation1. Many efforts have been focused on predicting MVI of HCCs using radiological findings in terms of preoperative imaging2. Recent advances in quantitative radiomics approaches3 have also been potentially be used as noninvasive prognosis or predictive biomarker for MVI4. However, those radiologic and radiomics features are generally limited by radiologist’s experience, which may be insufficient for MVI characterization. Deep feature derived from data-driven learning has consistently shown to outperform conventional radiologic and texture features for lesion characterization in medical imaging processing5. To this end, we propose a deep learning framework based on 3D Convolutional Neural Network (CNN) to extract discriminative information from HCCs in Contrast-enhanced MR for better MVI prediction.Methods
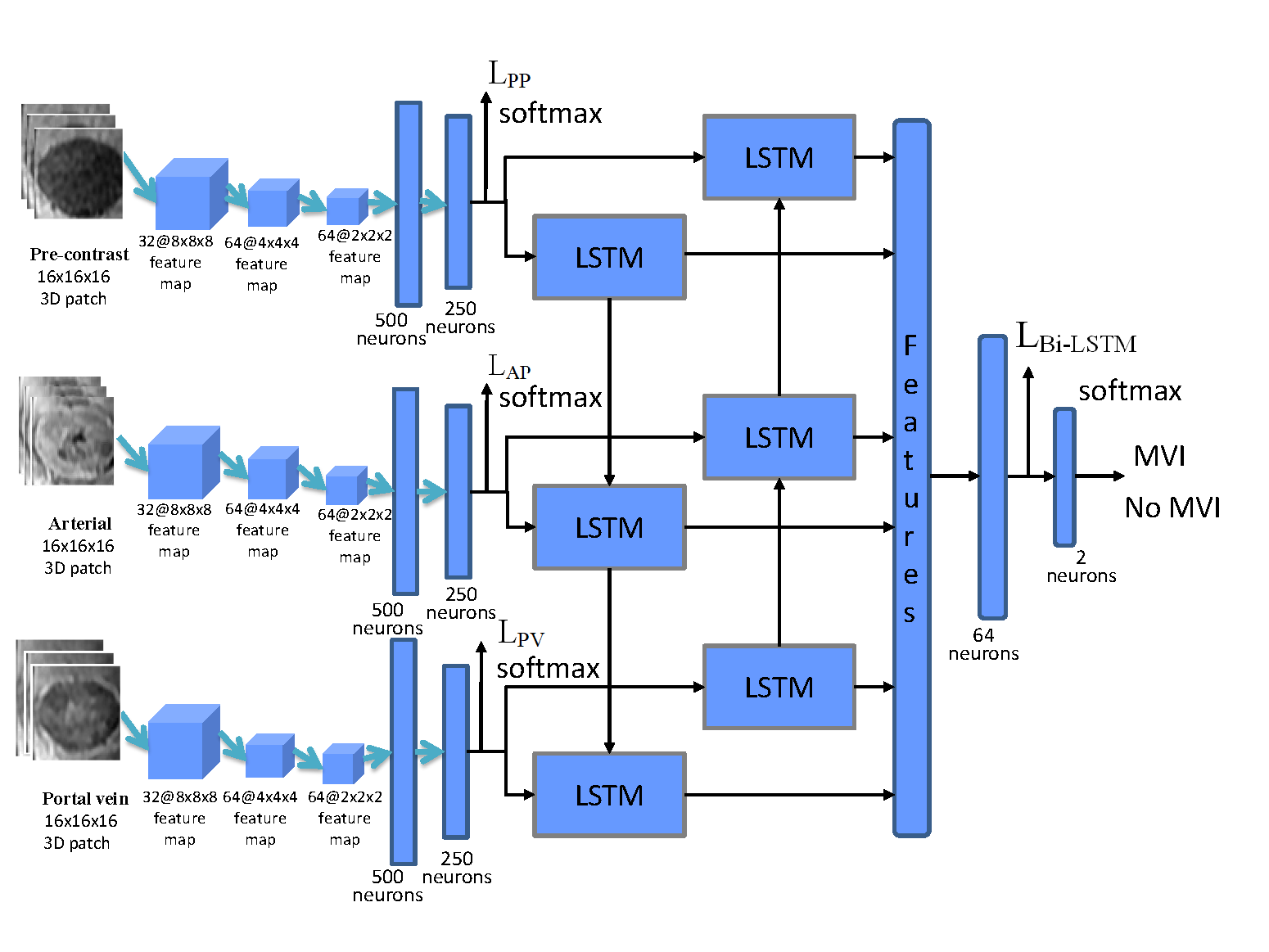
This retrospective study was approved by the local institutional review board. Sixty-three consecutive patients with 63 hisotologically proven HCCs after surgical resection from October 2012 to May 2017 were included for this retrospective study. Gd-DTPA-enhanced MR imaging were performed with a 3.0T MR scanner (Signa Excite HD 3.0T, GE Healthcare, Milwaukee, WI, USA). Of the 63 lesions, thirty-five were pathologically determined as the absence of MVI, while twenty-eight were pathologically determined as the presence of MVI. Figure 1 showed the framework of the proposed deep learning method. First, numerous 3D patches within the tumor region were separately extracted from the pre-contrast, arterial, and portal vein phases. Then, 3D CNN was adopted to extract spatially 3D deep features from those 3D patches for MVI prediction. Subsequently, 3D deep features from the pre-contrast, arterial and portal vein phases were then separately fed into the two layers Bi-directional LSTM network to extract temporal characteristics from the sequential data of Contrast-enhanced MR. Finally, a deeply supervised loss function6 that combines three loss functions of 3D CNN in the pre-contrast, arterial and portal vein phases and a loss function in the Bi-directional LSTM was designed as the total loss function of the proposed deep learning framework for MVI prediction. 4-fold cross-validation with 10 repetitions on the 63 HCCs was utilized to test the proposed framework.Results
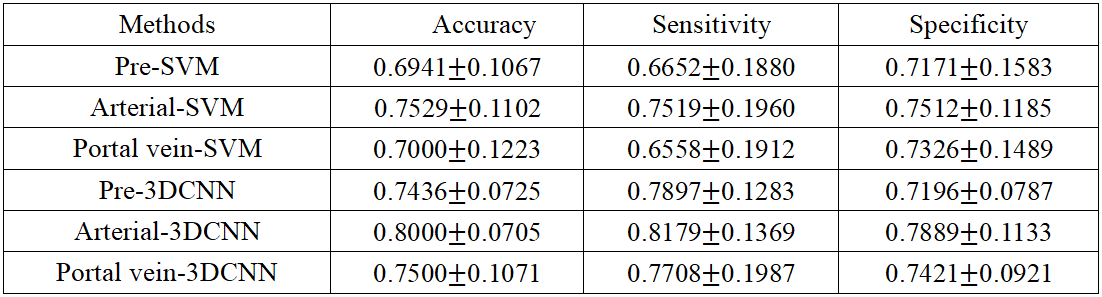
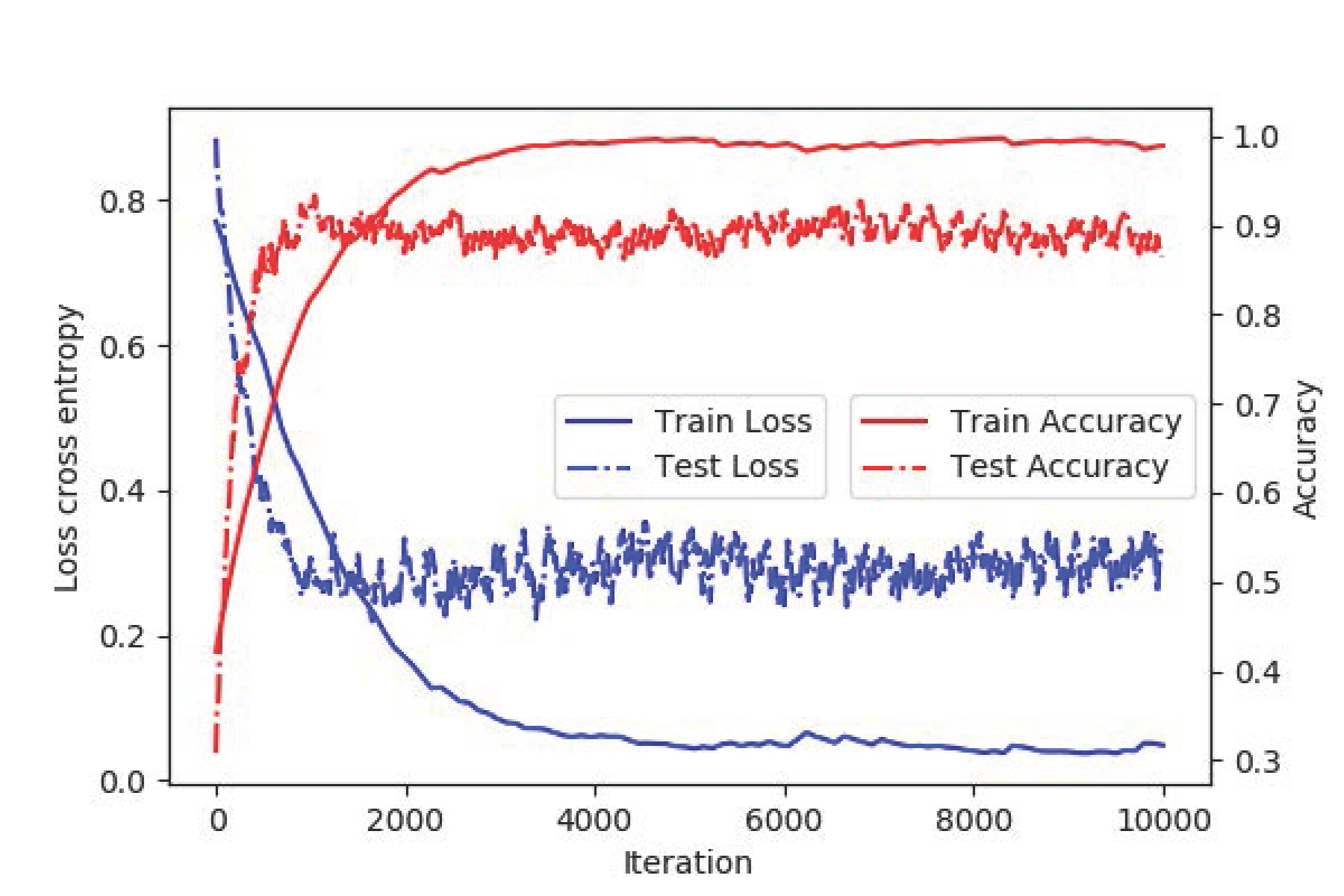
Table 1 showed the comparison performance of the proposed framework and the radiomic approach for MVI prediction. With respect to the pre-contrast, arterial and portal vein phases, the 3D deep features always yielded better results than those of the radiomics approach. As shown in Table 2, 3D deep feature concatenation (3D CNN_CON) from pre-contrast, arterial and portal vein phases could result in improved results than that of the single phase for MVI prediction. However, if we compare the performance of 3D deep feature concatenation and the proposed 3D CNN & Bi-LSTM framework, it can be found that the proposed 3D CNN & Bi-LSTM yielded much better results than that of the 3D CNN_CON in Table 2. Finally, the proposed deeply supervised loss function (3D_CNN_BiLSTM_COM) that integrates the spatial (3D CNN) and temporal information (Bi-SLTM) yielded the best results of MVI prediction. The curves of training loss, test loss and their corresponding accuracies were also shown in Figure 2.Discussion
With respect to each phase of Contrast-enhanced MR, we separately compared the proposed 3D deep learning framework with the radiomics approach, which is based on texture features and support vector machine7. Results in Table 1 indicated that 3D deep features outperformed texture features for MVI prediction. Compared the results in Table 1 and 2, it could be inferred that fusion of deep features from multimodality will be advantageous for MVI prediction. Then, we compared the proposed framework with the method of 3D deep feature concatenation with Contrast-enhanced MR images in order to demonstrate the efficacy of the adopted Bi-directional LSTM and the deeply supervised loss function. The proposed 3D CNN & Bi-LSTM yielded much better results than that of the 3D CNN_CON, suggesting that the temporal information of the Contrast-enhanced MR derived from the Bi-LSTM could provide additional significance for MVI prediction. As shown in Figure 2, the test loss gradually decreased and the test accuracy consistently increased, demonstrating that the problem of over-fitting with limited number of patients has not been observed in the proposed deep learning framework.Conclusion
In this study, we proposed a deep learning framework based on 3D CNN to extract discriminative information from HCCs of Contrast-enhanced MR images for better MVI prediction. Experimental results demonstrated that the proposed deep learning framework outperformed the radiomics approach and the method of 3D deep feature concatenation. Moreover, the proposed deeply supervised loss function that integrates the spatial and temporal information can yield best performance of MVI prediction.Acknowledgements
This research is sponsored by the grants from National Natural Science Foundation of China (81771920).References
[1]Unal E, Ldilman L, Akata D, Ozmen M, Karcaaltincaba M. Microvascular invasion in hepatocellular carcinoma. Diagn Interv Radiol 2016;22: 125-132.
[2]Renzulli M, Brocchi S, Cucchetti A, et al. Can Current Preoperative Imaging Be Used to Detect Microvascular Invasion of Hepatocellular Carcinoma? Radiology 2016; 279(2):432-442.
[3] Limkin EJ, Sun R, Dercle L, et al. Promises and challenges for the implementation of computational medical imaging (radiomics) in oncology. Ann Oncol 2017 Jun 1;28(6):1191-1206.
[4] Peng J, Zhang J, Zhang Q, Xu Y, Zhou J and Liu Li. A radiomics nomogram for preoperative prediction of microvascular invasion risk in hepatitis B virus-related hepatocellular carcinoma. Diagn Interv Radiol 2018; 24:121-127.
[5] Greenspan H, Ginneken B.V, Summers R.M. Deep Learning in Medical Imaging: Overview and Future Promise of an Exciting New Technique. IEEE Trans Med Imaging 2016;35(5):1153-1159.
[6] Lee CY, Xie S, Gallagher P, Zhang Z, Tu Z. Deeply-supervised nets. Artificial Intelligence and Statistics 2015:562-570.
[7] Zhou W, Wang Q, Wang G, et al. Differentiationof low- and high- grade hepatocellular carcinomas withtexture features and a machine learning model in arterialphase of Contrast-enhanced MR. Proc. Intl. Soc. Mag.Reson. Med. 2017; 25: 4959.
Figures