0672
Learning Systematic Imperfections and Image Reconstruction with Deep Neural Networks for Wave-Encoded Single-Shot Fast Spin Echo1Electrical Engineering, Stanford University, Stanford, CA, United States, 2Radiology, Stanford University, Stanford, CA, United States, 3GE Healthcare, Menlo Park, CA, United States
Synopsis
Wave-encoded single-shot fast spin echo imaging (SSFSE) achieves good structural delineation in less than a second while its calibration and reconstruction usually take more than a minute to finish. This study proposes a method to accelerate the calibration and reconstruction for wave-encoded SSFSE with a deep-learning-based approach. This method first learns the systematic imperfections with a deep neural network, and then reconstructs the image with another unrolled convolutional neural network. The proposed approach achieves 2.8-fold speedup compared with conventional approaches. Further, it can also reduce the ghosting and aliasing artifacts generated in conventional calibration and reconstruction approaches.
Target audience
MR scientists working on MRI reconstruction.Purpose
Single-shot fast spin echo (SSFSE) imaging has been routinely used in clinical abdominal scans to achieve T2-weighting. When combined with variable-density under-sampling and wave encoding, SSFSE achieves good structural delineation within 500 ms per slice[1]. However, wave encoding usually requires waveform calibration due to systematic imperfections, such as gradient delays, eddy currents, and inaccurate isocenter locations. This calibration may take several seconds to calculate [1]. The result is reconstruction lags and queues in the scanner workflow, since the reconstruction of 2D wave-encoded SSFSE images can only begin after the waveform calibration finishes. In this study, we propose to simultaneously accelerate the calibration and reconstruction for wave-encoded SSFSE with a deep-learning-based approach, which first learns the systematic imperfections with a deep neural network, and then reconstructs the images with another unrolled network[2].Methods
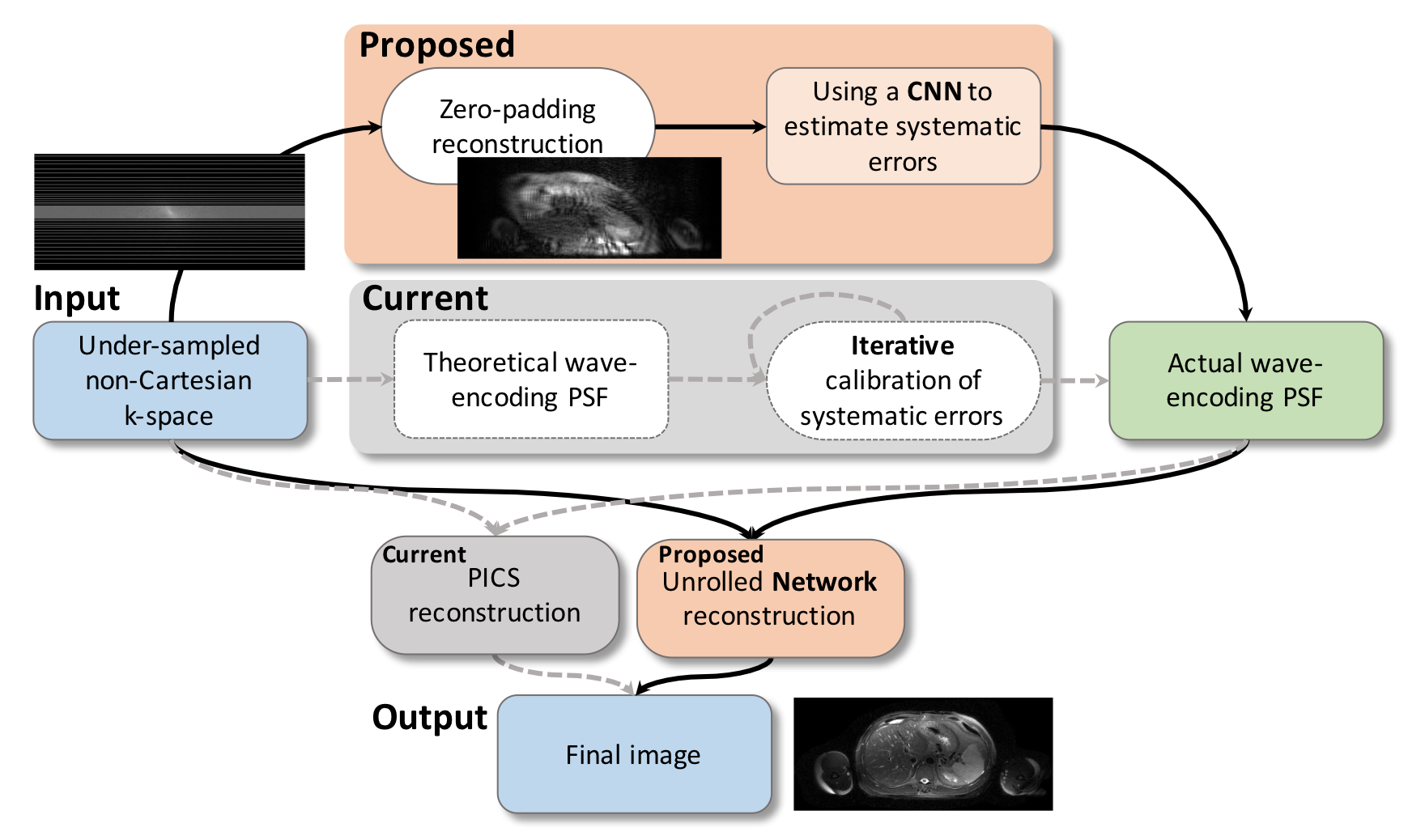
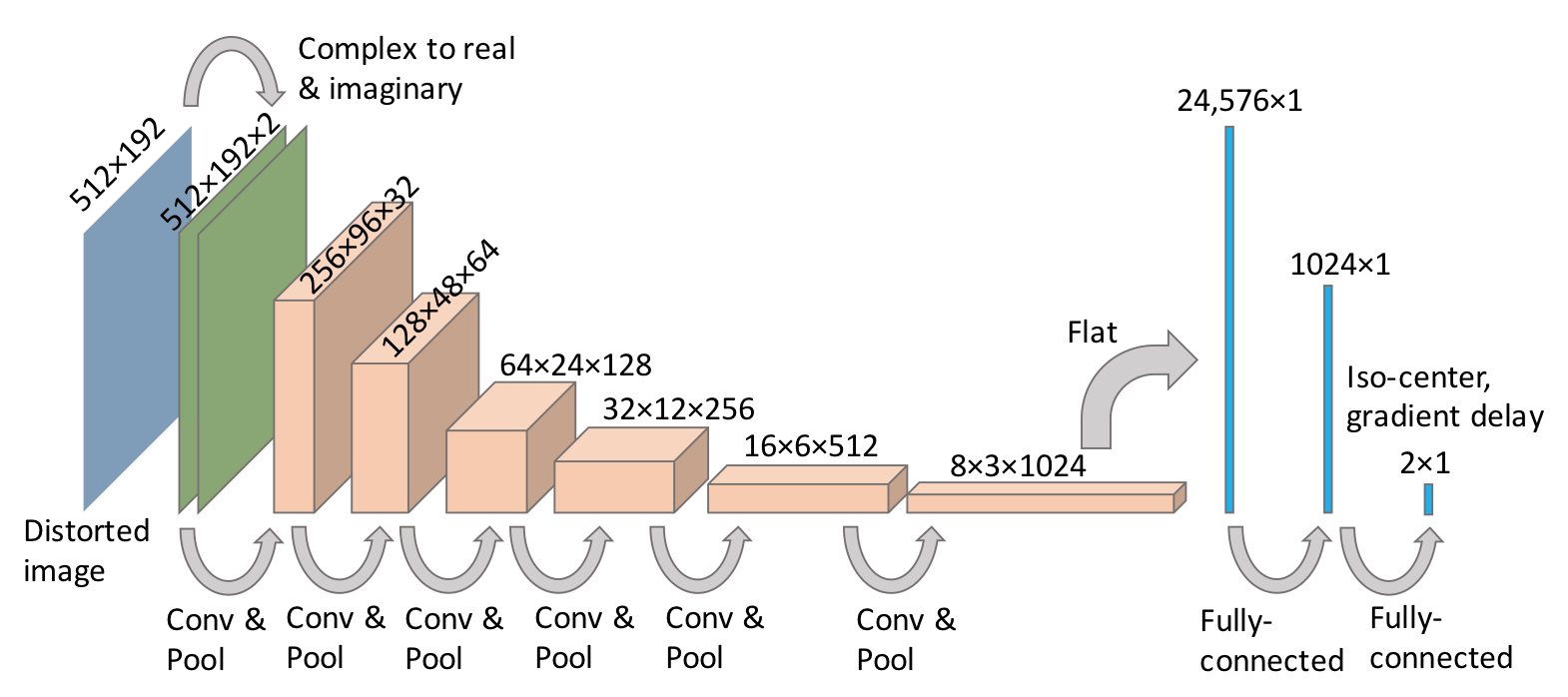
In the waveform calibration and image reconstruction workflow (Fig.1), we replaced an iterative optimization-based calibration[1] with a zero-padded reconstruction and a deep neural network. This network outputs the estimated systematic gradient delay and the relative isocenter location with respect to the prescribed field-of-view (FOV). Zero-padded reconstructions based on theoretical point-spread-functions (PSF) were used as the input to the convolutional neural network (CNN). The CNN contains (a) the concatenation of the real and imaginary data, (b) six convolutional and pooling layers with a kernel size of 5x5 and ReLU activation, and (c) two fully-connected layers outputting a 2x1 tensor indicating the predicted parameters (Fig. 2).
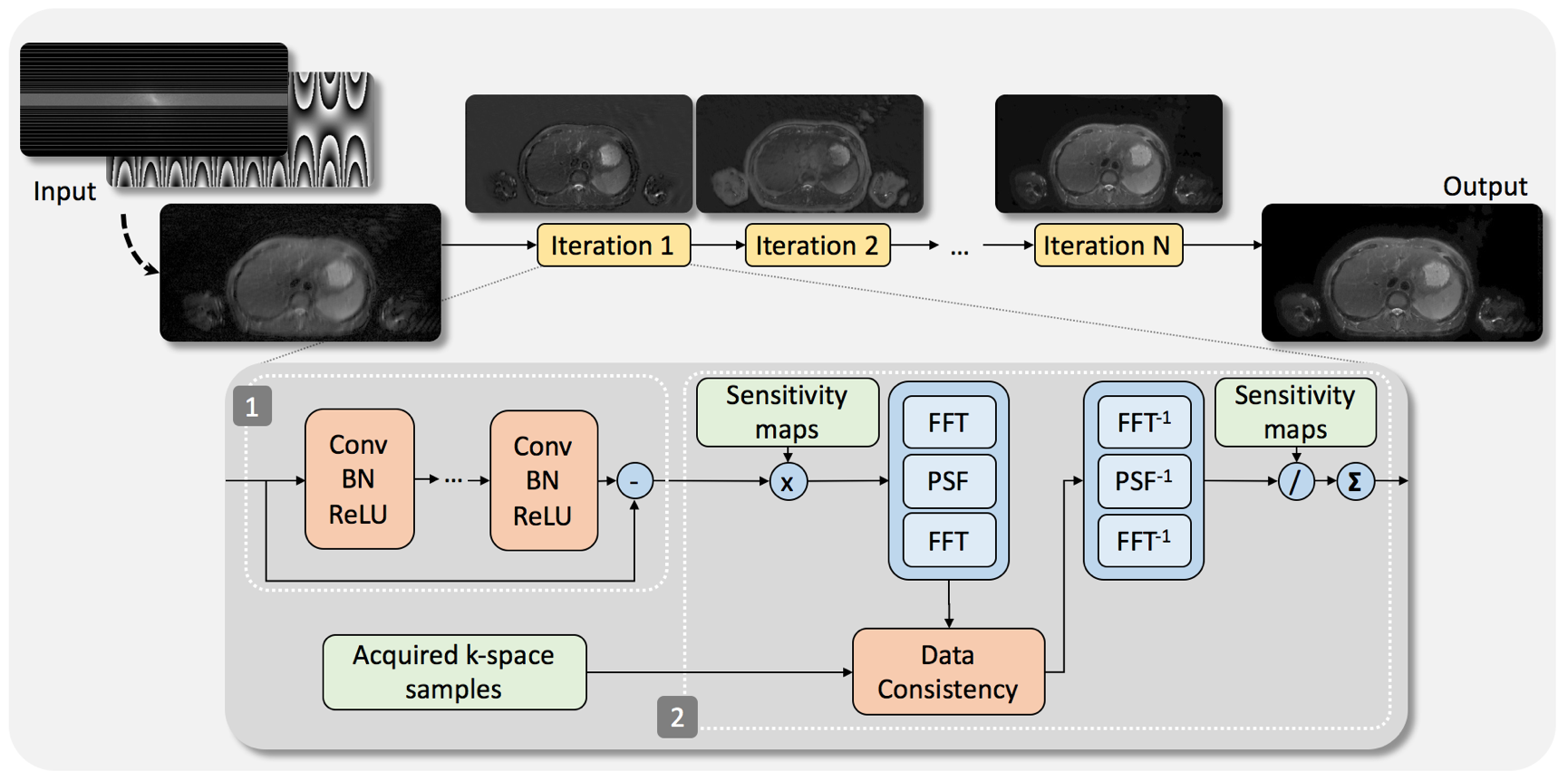
We also replaced the iterative parallel imaging and compressed sensing (PICS) reconstruction[3] with an unrolled network[2] to output reconstructed images. Raw wave-encoded k-space and the corresponding wave-encoding PSFs were used as the inputs. The unrolled network includes four iterations of CNNs and data consistency steps. Each CNN contains 5 convolutional layers with 64 features and a kernel size of 5x5 (Fig. 3).
The two networks for calibrating systematic imperfections and reconstructing images were trained separately. To train the first network, we collected 2180 2D wave-encoded SSFSE abdominal images (1721 used for training and 459 used for evaluation) on GE MR750 3T scanners with IRB approval, and reconstructed them with conventional PICS[3]. To augment the training data and reduce overfitting, under-sampled wave-encoded k-space data were retrospectively generated from PICS reconstructions with randomly simulated system imperfections. The same datasets were used to train the second network, with PICS reconstructions used as the ground truths.
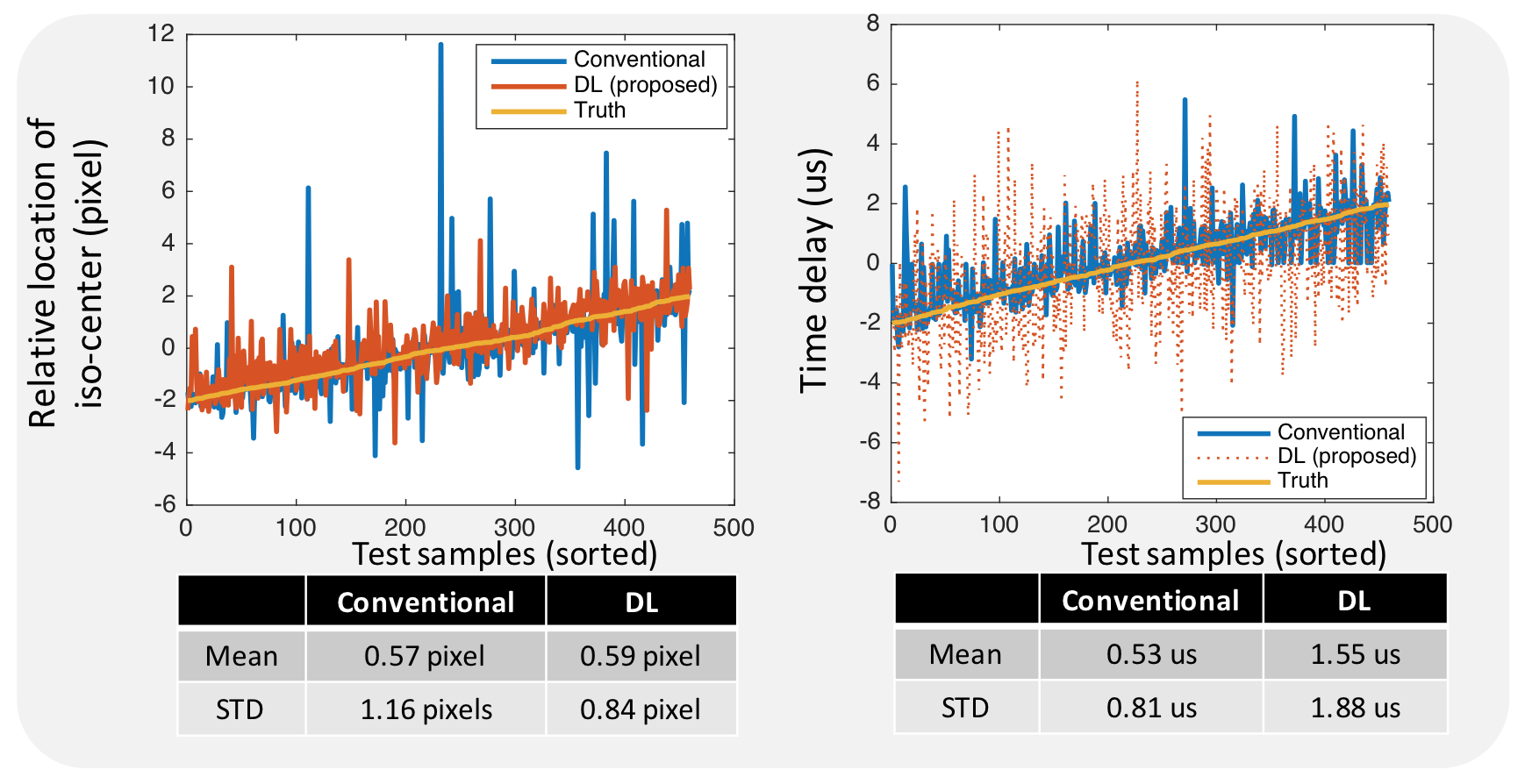
Both training and testing were implemented in Tensorflow. Training of the first network was performed with a batch size of 48 and L1 loss, and the second network was trained with a batch size of 3 and L1 loss. The accuracy of the imperfection calibration network was evaluated based on the mean estimation error and standard deviation (STD) of the errors. A conventional iterative PSF calibration approach[1] was implemented for comparison. Root-mean-squared errors (RMSE) between the PICS reconstructions and the unrolled-network outputs were also evaluated. Reconstruction time was recorded on an NVIDIA 1080Ti GPU.
Results
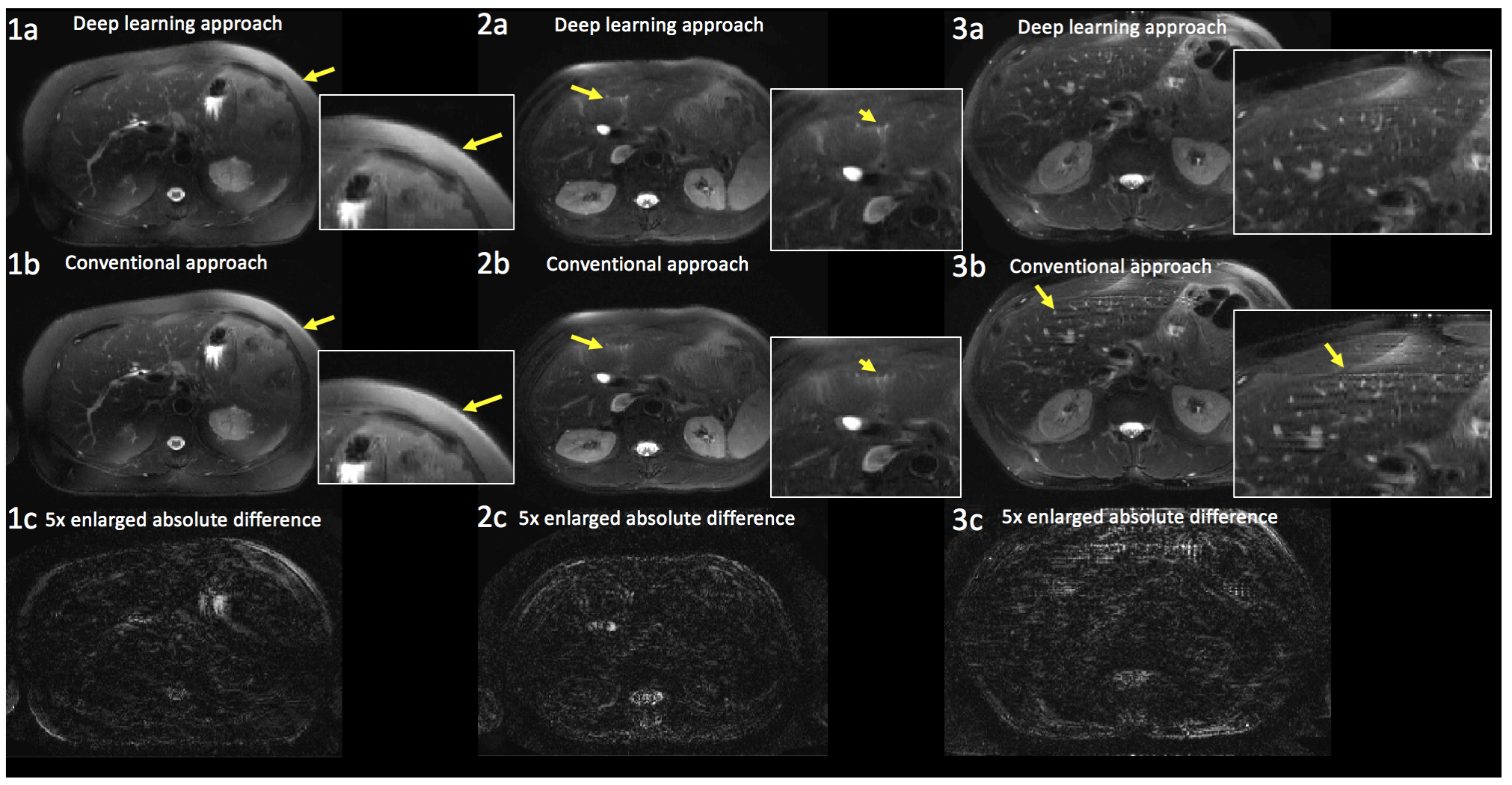
The proposed deep-learning approach for calibrating systematic imperfections achieved similar accuracy in estimating the isocenter (mean difference 0.59 pixel for deep-learning approach and 0.57 pixel for the conventional approach), and lower accuracy in estimating the time delay (1.55us), compared with the iterative approach (0.53us) (Fig. 4). Test images reconstructed with the trained unrolled network yielded a normalized RMSE of 11.3±2.7% compared with PICS. Representative examples of the deep-learning-based reconstruction are shown in Fig. 5. In one test case, the conventional approach converged to an incorrect local minimum (Fig. 5 (2a-c)). However, the proposed approach was able to reduce ghosting artifacts caused by uncompensated system imperfections with the conventional approach, as indicated by arrows in Fig. 5 (2a-c). In some cases, the unrolled network achieved fewer aliasing artifacts than conventional PICS reconstruction (Fig. 5 (3a-c)). The overall average reconstruction time of the proposed approach was 29.9±2.3 sec, while conventional iterative calibration and PICS reconstruction took 83.4±8.6 sec.Discussion and Conclusion
We trained two deep neural networks and combined them together to calibrate systematic imperfections and to reconstruct the final image based on the deep-learning-calibrated PSF. Deep-learning-based imperfection calibration achieved similar accuracy in isocenter estimation compared to the conventional PSF calibration approach, while yielding higher error in time delay estimation. Combined with the unrolled network for image reconstruction, the proposed calibration and reconstruction pipeline achieved 2.8-fold speedup. This approach can also reduce artifacts generated in conventional calibration and reconstruction, caused by imperfect waveform calibration or under-sampling. It could also be applied to reconstructing other non-Cartesian acquisitions, such as spirals[4] and cones[5].Acknowledgements
GE Healthcare, NIH R01 EB009690.References
1. Chen F. et al. JMRI; 47 (4), 954-966.
2. Cheng JY, et al. arXiv preprint arXiv:1805.03300. 2018 May 8.
3. Uecker M, et al. MRM; 71:990–1001.
4. Glover GH. MRM; 42(2):412-5.
5. Gurney PT, et al. MRM; 55(3):575-82.
Figures