0659
DL-ESPIRiT: Improving robustness to SENSE model errors in deep learning-based reconstruction1Electrical Engineering, Stanford University, Stanford, CA, United States, 2Applied Sciences Laboratory, GE Healthcare, Menlo Park, CA, United States, 3Radiology, Stanford University, Stanford, CA, United States
Synopsis
Parallel imaging concepts, such as sensitivity encoding (SENSE), have been incorporated into DL reconstruction frameworks by augmenting the acquisition model with knowledge of the coil sensitivities. However, SENSE-based methods rely on accurate estimation of sensitivity maps; otherwise, residual aliasing may arise due to model errors such as in reduced field-of-view imaging. Here we propose DL-ESPIRiT, an ESPIRiT-based neural network architecture with improved robustness to model errors. We show that DL-ESPIRiT can reconstruct 10X accelerated 2D cardiac CINE data with higher fidelity and allow for more accurate automatic assessment of cardiovascular function than l1-ESPIRiT.
Purpose
Deep learning-based (DL) reconstruction methods1,2 utilize convolutional neural networks (CNNs) to implicitly learn better priors to enable faster scan times than conventional compressed sensing. Model-based methods have incorporated parallel imaging (PI) concepts, such as sensitivity encoding (SENSE3), into DL reconstruction by augmenting the acquisition model with explicit knowledge of the coil sensitivities4. However, SENSE-based methods rely on accurate estimation of sensitivity maps during the calibration step; otherwise, residual ghosting may arise from SENSE model errors. For example, the infamous “SENSE ghost”5 appears when attempting to reconstruct an aliased object that is larger than the prescribed field-of-view (FOV). ESPIRiT6 has been shown to be robust to such errors by representing overlapping anatomy using multiple sets of sensitivity maps. Here we explore the effect of anatomy overlap in PI/DL reconstruction and propose an ESPIRiT-based unrolled network architecture to address model errors. Our method, DL-ESPIRiT, is compared against l1-ESPIRiT on 10x accelerated 2D cardiac CINE data and evaluated with respect to common image quality metrics and quantitative measures of cardiovascular function. With reduced FOV and high acceleration rate, we aim to acquire full coverage short-axis cardiac CINE data in a single breath-hold.
Methods
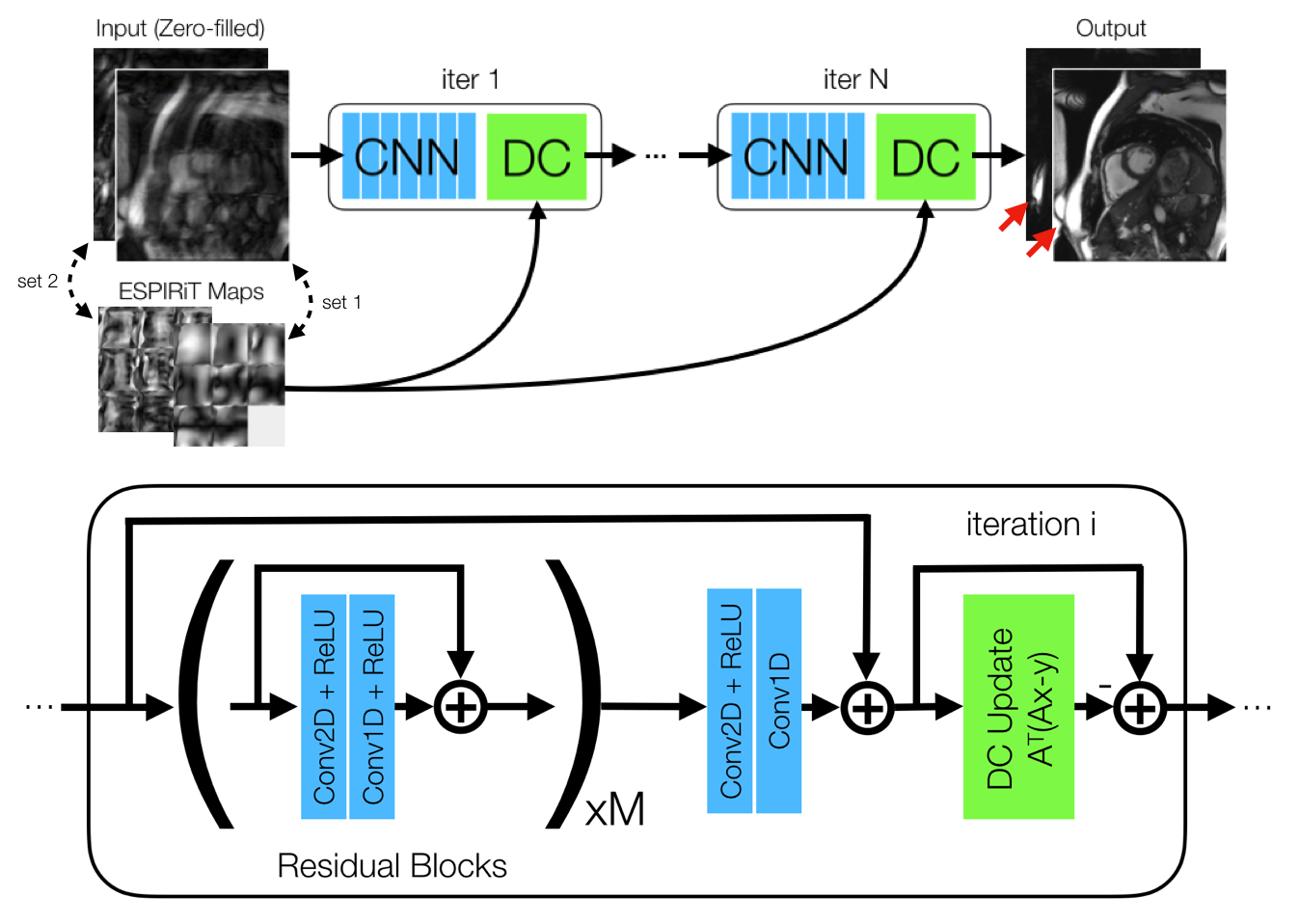
Network Architecture: The proposed unrolled network architecture7,8 iterates between 3D CNNs and data consistency steps, which models the projection between k-space and image domains using multiple sets of sensitivity maps estimated using ESPIRiT (Fig. 1). Multiple coil-combined images, each corresponding to a set of maps, are stacked and jointly de-aliased by residual network blocks9 composed of separable 3D convolutions10,11. Separate networks are trained to use one and two sets of maps to evaluate differences in robustness to anatomy overlap. Each network is trained end-to-end on the average L1-loss between output and ground truth image sets using the Adam optimizer12 on two NVIDIA GTX 1080 Ti cards.
Training Data: With IRB approval, fully sampled bSSFP 2D cardiac CINE datasets were acquired from 15 volunteers at different cardiac views and slice locations on 1.5T and 3.0T GE scanners using a 32-channel cardiac coil. All datasets are coil compressed13 to 8 channels for speed and memory considerations. For training, 12 volunteer datasets are split slice-by-slice to create 180 unique examples, which are further augmented by random flipping, spatial and temporal translation, cropping along readout, reducing phase FOV (0-15%) to simulate anatomy overlap, partial echo (20-30%), and variable-density undersampling (R=7.5-10.5).
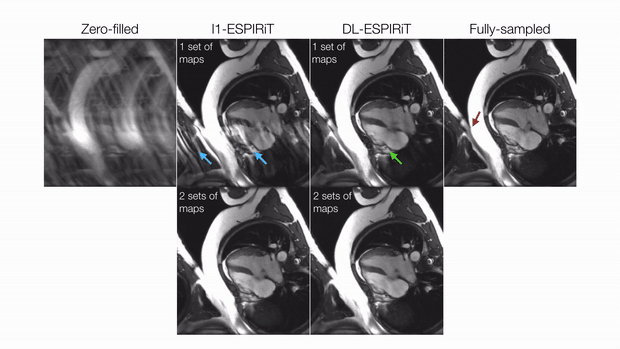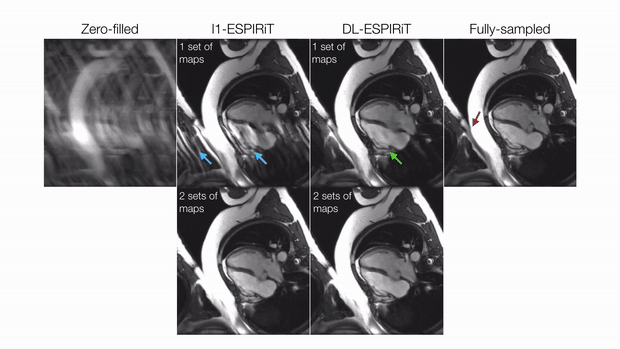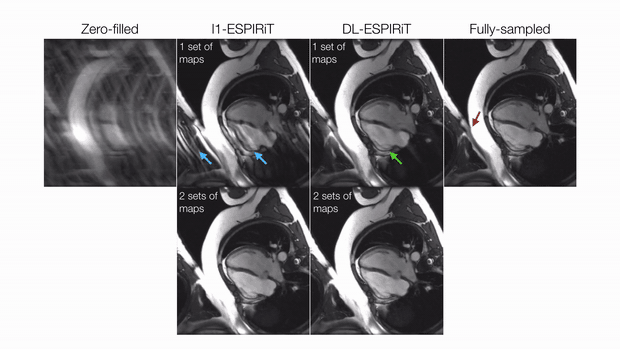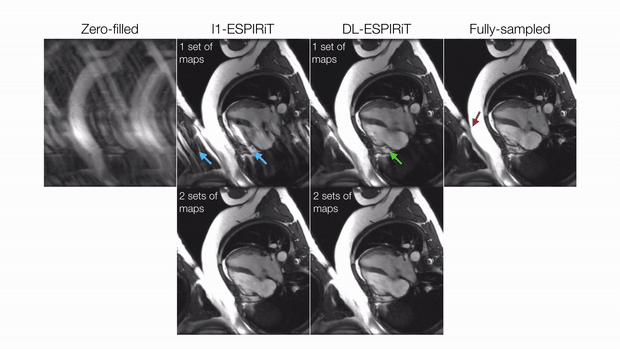
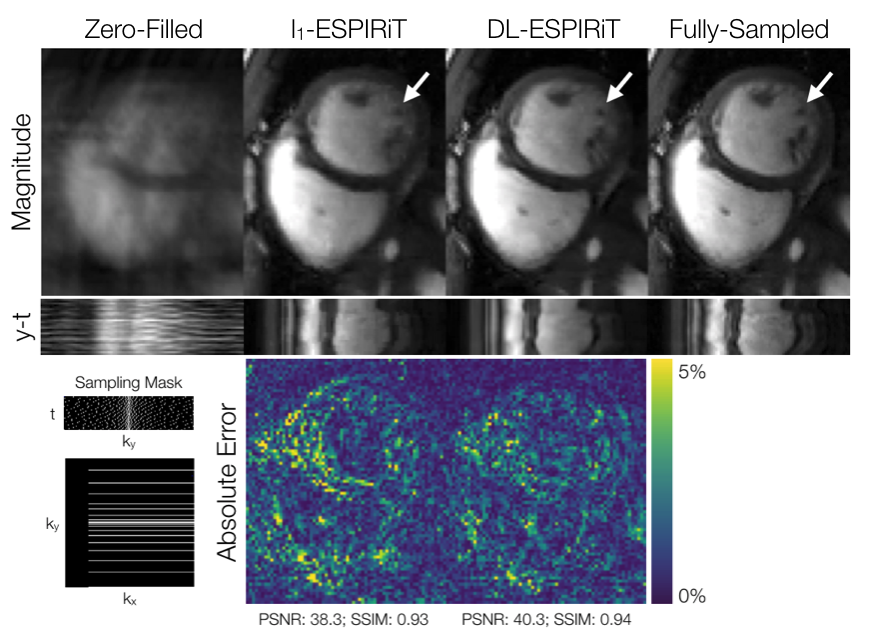
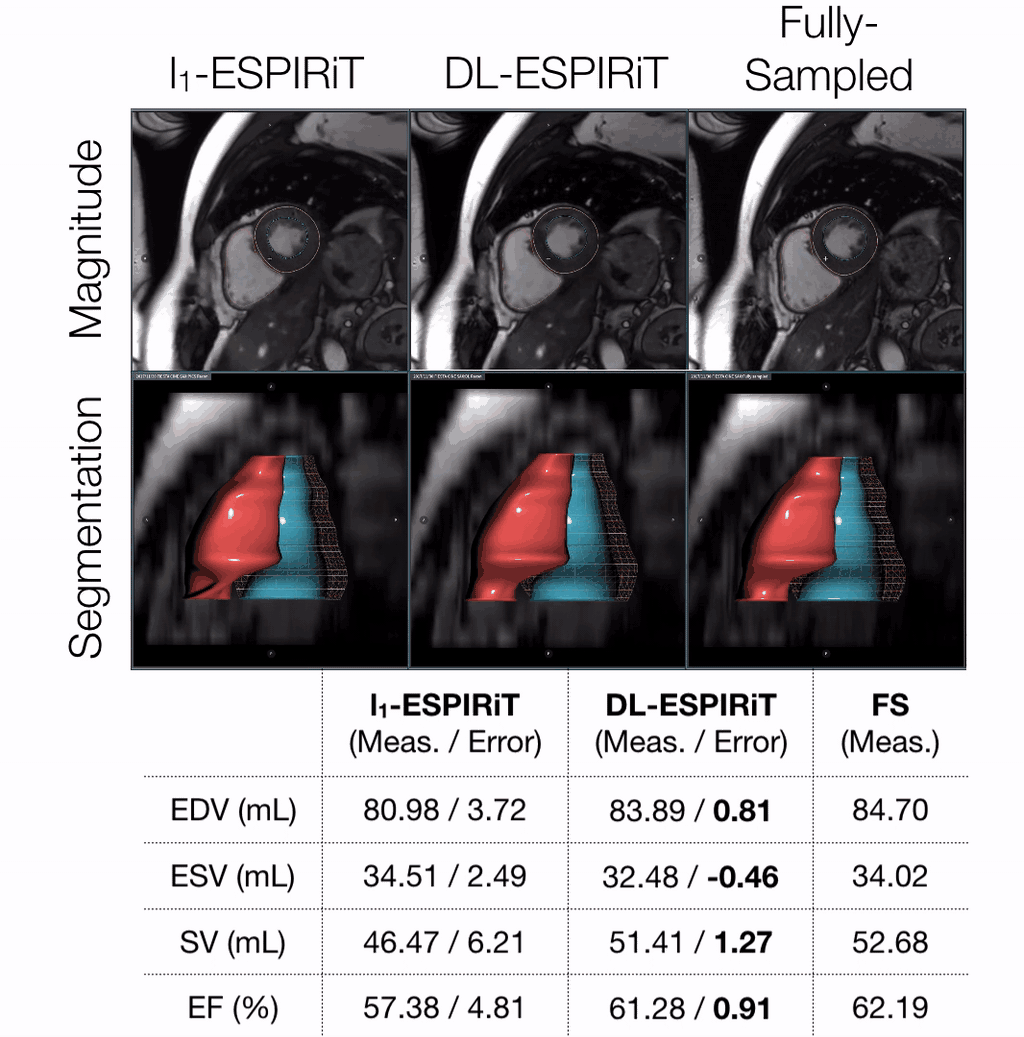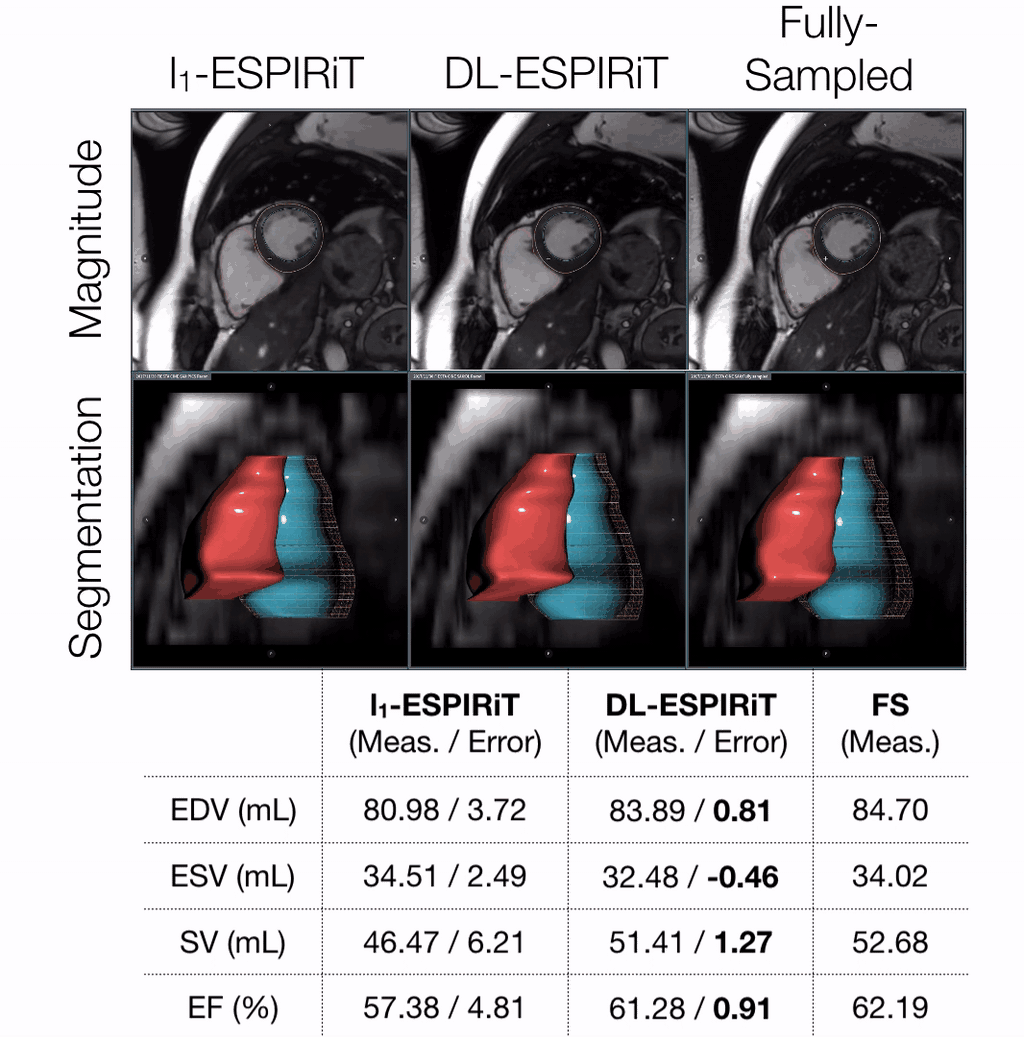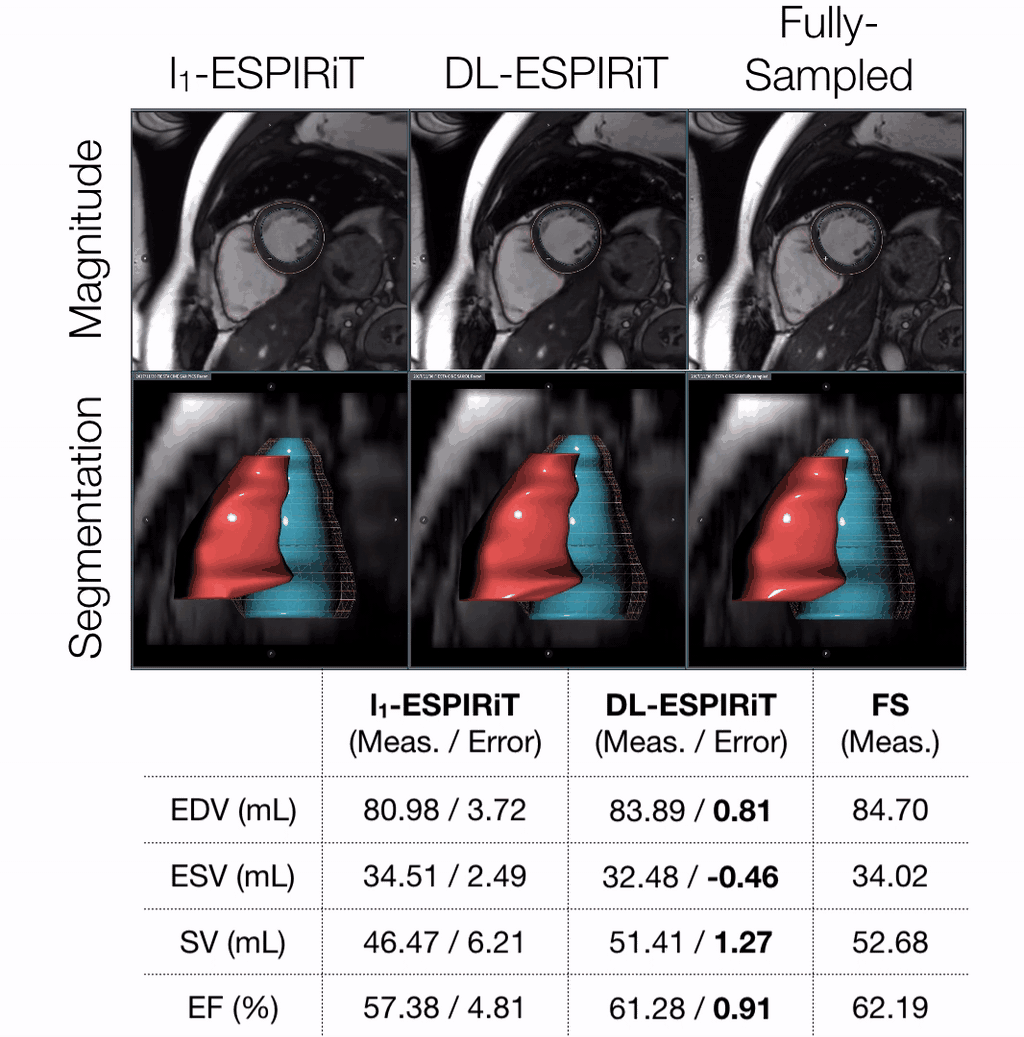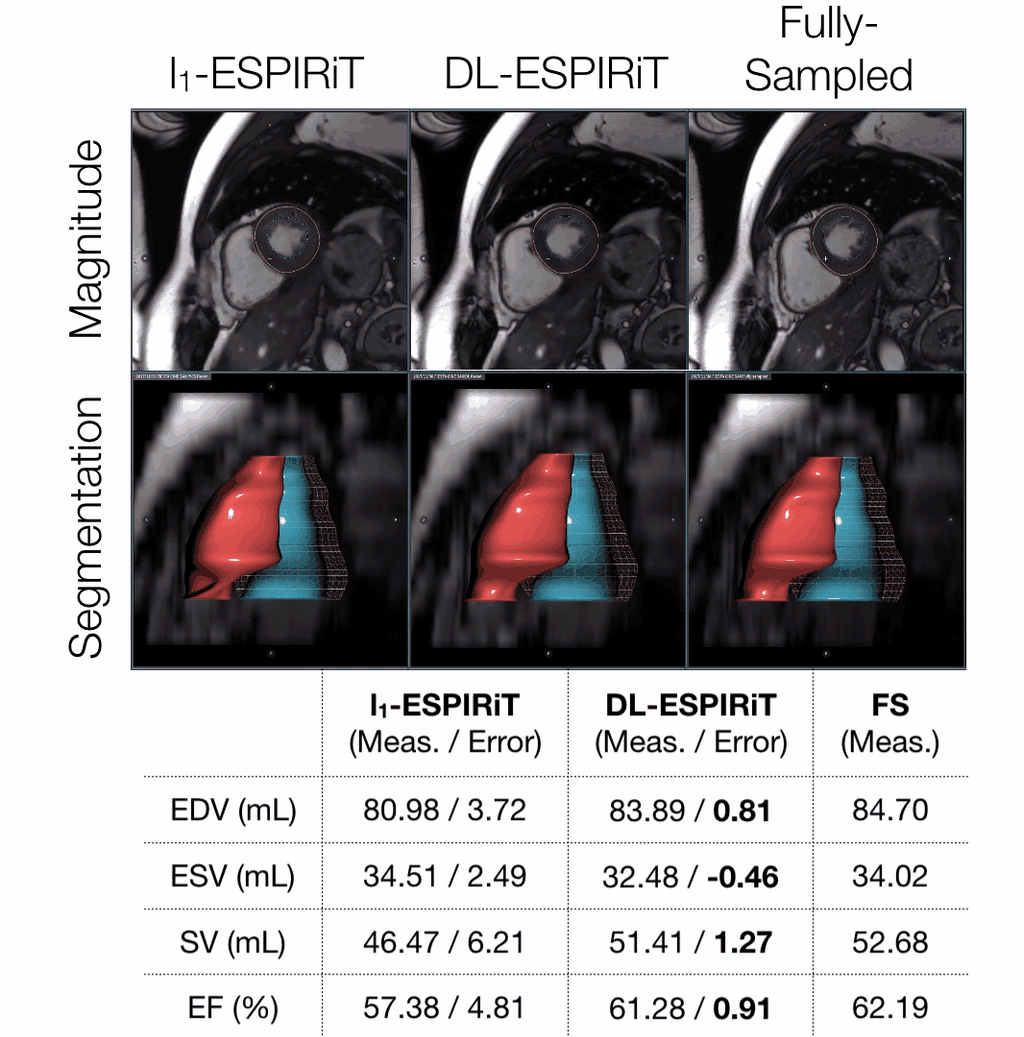
Evaluation: For evaluation, the remaining three volunteer datasets were retrospectively undersampled to simulate a 25 second acquisition with 10X acceleration and 25% partial echo. These were reconstructed slice-by-slice using the proposed method and l1-ESPIRiT with two sets of maps and spatial and temporal total variation (TV) constraints. Reconstruction quality was evaluated with respect to peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM). Quantitative measurements of left ventricular (LV) volume and ejection fraction were computed from deep learning-based, automatic segmentations14 of epicardial and endocardial LV borders.
Results
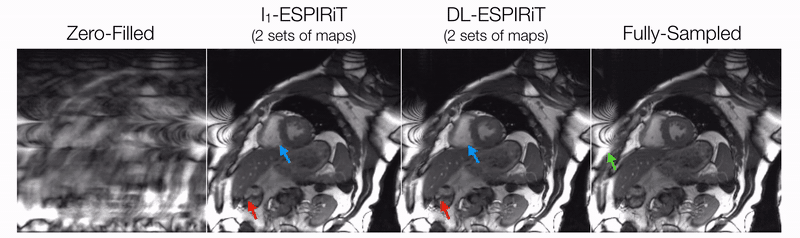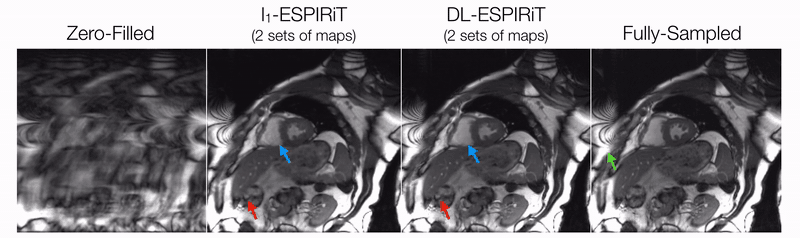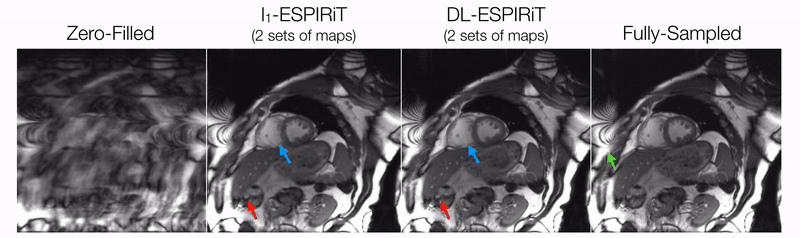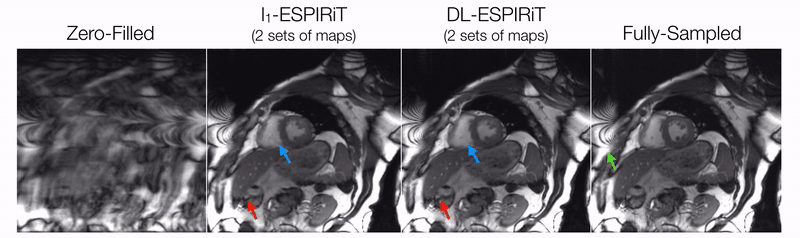
DL-ESPIRiT depicts significantly less aliasing due to anatomy overlap than l1-ESPIRiT in single map reconstructions (Fig. 2). In double map reconstructions, we show an example where DL-ESPIRiT is able to resolve overlap-related aliasing that l1-ESPIRiT could not (Fig. 3). DL-ESPIRiT outperforms l1-ESPIRiT with respect to both PSNR and SSIM metrics (Fig. 4, bottom). The improvement of the proposed method over l1-ESPIRiT is most apparent around endocardial borders with less spatiotemporal blurring of myocardium and papillary muscles (Fig. 4). Furthermore, automatic segmentations of DL-ESPIRiT images produce more accurate LV function measurements than automatic segmentations of l1-ESPIRiT images (Fig. 5).Discussion & Conclusion
Here we propose an ESPIRiT-based deep learning framework for robust reconstruction at reduced FOVs that do not cover the entire object. Using a single set of maps, DL-ESPIRiT is able to significantly reduce aliasing despite using an acquisition model that cannot adequately capture overlapping anatomy. This suggests that DL-ESPIRiT may be more robust than l1-ESPIRiT to other model errors (i.e. motion, distortions due to gradient non-linearity) as long as they can be simulated in the training dataset. Further studies are necessary to compare against GRAPPA-based deep reconstruction algorithms15,16 which do not depend on sensitivity maps and therefore also exhibit robustness to model errors.
Furthermore, DL-ESPIRiT is capable of learning better spatiotemporal priors to represent heart anatomy and motion more naturally than TV constraints in l1-ESPIRiT for highly accelerated scans. Better representation of dynamics can result in more accurate segmentations and quantitation in an end-to-end deep learning processing framework for cardiovascular applications.
Acknowledgements
National Science Foundation Graduate Research Fellowship (DGE-114747), NIH R01EB009690, GE HealthcareReferences
1. J. Schlemper, J. Caballero, J. V. Hajnal, A. Price, and D. Rueckert, “A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction,” IEEE Trans. Med. Imaging, vol. 37, no. 2, pp. 491–503, 2018.
2. C. Qin, J. V Hajnal, D. Rueckert, J. Schlemper, J. Caballero, and A. N. Price, “Convolutional Recurrent Neural Networks for Dynamic MR Image Reconstruction.,” IEEE Trans. Med. Imaging, Aug. 2018.
3. K. P. Pruessmann, M. Weiger, M. B. Scheidegger, and P. Boesiger, “SENSE: Sensitivity encoding for fast MRI,” Magn. Reson. Med., vol. 42, no. 5, pp. 952–962, 1999.
4. K. Hammernik, T. Klatzer, E. Kobler, M. P. Recht, D. K. Sodickson, T. Pock, and F. Knoll, “Learning a variational network for reconstruction of accelerated MRI data,” Magn. Reson. Med., 2018.
5. J. W. Goldfarb, “The SENSE ghost: Field-of-view restrictions for SENSE imaging,” J. Magn. Reson. Imaging, vol. 20, pp. 1046–1051, 2004.
6. M. Uecker, P. Lai, M. J. Murphy, P. Virtue, M. Elad, J. M. Pauly, S. S. Vasanawala, and M. Lustig, “ESPIRiT - An eigenvalue approach to autocalibrating parallel MRI: Where SENSE meets GRAPPA,” Magn. Reson. Med., 2014.
7. S. Diamond, V. Sitzmann, F. Heide, and G. Wetzstein, “Unrolled Optimization with Deep Priors,” arXiv:1705.08041 [cs.CV], 2017.
8. J. Y. Cheng, F. Chen, M. T. Alley, J. M. Pauly, and S. S. Vasanawala, “Highly Scalable Image Reconstruction using Deep Neural Networks with Bandpass Filtering,” arXiv:1805.03300 [cs.CV], 2018.
9. K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
10. D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun, and M. Paluri, “A Closer Look at Spatiotemporal Convolutions for Action Recognition,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
11. C. M. Sandino, P. Lai, S. S. Vasanawala, and J. Y. Cheng, “Deep Reconstruction of Dynamic MRI Data Using Separable 3D Convolutions,” in ISMRM Workshop On Machine Learning Part 2, Washington D.C., 2018.
12. D. P. Kingma and J. L. Ba, “Adam: A method for stochastic gradient descent,” ICLR Int. Conf. Learn. Represent., 2015.
13. T. Zhang, J. Y. Cheng, Y. Chen, D. G. Nishimura, J. M. Pauly, and S. S. Vasanawala, “Robust self-navigated body MRI using dense coil arrays,” Magn. Reson. Med., vol. 76, no. 1, pp. 197–205, 2015.
14. J. Lieman-Sifry, M. Le, F. Lau, S. Sall, and D. Golden, “FastVentricle: Cardiac segmentation with E-Net,” in International Conference on Functional Imaging and Modeling of the Heart, 2017.
15. M. Akçakaya, S. Moeller, S. Weingärtner, and K. Ugurbil, “Scan‐specific robust artificial‐neural‐networks for k‐space interpolation (RAKI) reconstruction: Database‐free deep learning for fast imaging,” Magn. Reson. Med., 2018.
16. Y. Han and J. C. Ye, “k-Space
Deep Learning for Accelerated MRI,” arXiv:1805.03779 [cs.CV], 2018.
Figures