0476
Multi-Shot Diffusion MRI using Deep MUSSELS1University of Iowa, Iowa City, IA, United States
Synopsis
This work proposes a deep-learning based computationally efficient method to reduce phase errors in multi-shot diffusion-weighted images. Recently, we introduced a navigator-free method to reduce these errors using structured low-rank matrix completion based approach termed as MUSSELS. This approach produces state-of-the-art results but is computationally expensive and requires a matrix lifting to estimate filter bank for each direction and slice, independently. We propose a generic deep-learning based approach to estimate phase errors for an unseen dataset by pre-learning the denoiser from exemplary data. The resulting model-based deep learning architecture reduces the computation time by a factor of around 450 with comparable reconstruction quality.
Introduction
Diffusion-weighted imaging (DWI) is widely used in neuroscience applications to study the microstructural and connectivity changes in the brain. The acquisition is typically performed using single-shot echo planar imaging (ssEPI) due to its high temporal efficiency and ability to freeze motion. However, ssEPI are prone to geometric distortions and blurring artifacts due to its long readout duration. To limit these artifacts, the k-space acquisition is segmented into multiple short readouts in the multi-shot EPI (msEPI) methods. However, subtle physiological motion during the diffusion encoding gradients results in the phase inconsistencies between shots leading to ghosting artifacts.
To overcome the phase inconsistency problem, we recently introduced the multi-shot sensitivity encoded structured low-rank matrix completion approach (MUSSELS) $$$^1$$$, which recovers the DWIs from msEPI acquisitions. While the algorithm results in state-of-the-art reconstructions, it is computationally expensive for whole brain studies with a large number of diffusion directions. In this work, we introduce a deep learning MUSSELS algorithm based on our recent model-based deep learning (MoDL) $$$^2$$$ framework to speed up the reconstruction by several orders of magnitude.
Proposed Method
The proposed deep learning architecture is motivated by the iterative reweighted least squares formulation of the MUSSELS problem. MUSSELS formulates the recovery of k-space of multi-shot data $$$ \widehat{\mathbf P}$$$ from its Fourier measurements $$$\mathbf y$$$ as: $$\text{arg}\min_{\widehat{\mathbf P},\mathbf Z} \underbrace{\|\mathcal {A}(\widehat{\mathbf P} )-\mathbf y \|_2^2}_{\text{Data Consistency}} + \lambda\underbrace{\|\mathbf{T}(\widehat{\mathbf Z})\|_*}_{\text{low rank prior}} + \beta\underbrace{\|\widehat{\mathbf P}-\mathbf Z\|_F^2}_{\text{regularization}} $$where $$$\mathcal{A}=\mathcal{S}\circ \mathcal{F} \circ \mathcal {C} \circ\mathcal{F}^{-1}$$$. Here, $$$\mathcal{F}$$$, $$$\mathcal{S}$$$, and $$$\mathcal{C}$$$ denotes the Fourier transform, sampling operation, and weighting with coil sensitivities, respectively. $$$\mathbf T(\mathbf Z)$$$ is a structured block-Hankel matrix representing the convolution between different shots and the phases. The IRLS based solution to above problem iterates between two steps. The first step involves estimation of nullspace $$$\mathbf G_n$$$ from the current iterate $$$\mathbf Z_n$$$. In the second step, the auxiliary variable $$$\mathbf Z$$$ is updated by projecting orthogonal to the nullspace specified by columns of $$$\mathbf G$$$: $$\text{MUSSELS D}_w\text{ step: } \mathbf Z_{n+1} \approx \left[\mathbf I- \frac{\lambda}{\beta} \mathbf{G_n}^H\mathbf G_n\right]\widehat{\mathbf P}_{n+1}\quad\quad\cdots\cdots(1)$$This update operation can be interpreted as a denoising operation as represented by the block diagram in Fig. 1. The main challenge with MUSSELS is the estimation of $$$\mathbf G$$$, which involves the computationally expensive matrix lifting operation. Note that $$$\mathbf G$$$ need to be estimated for each direction and slice, independently.
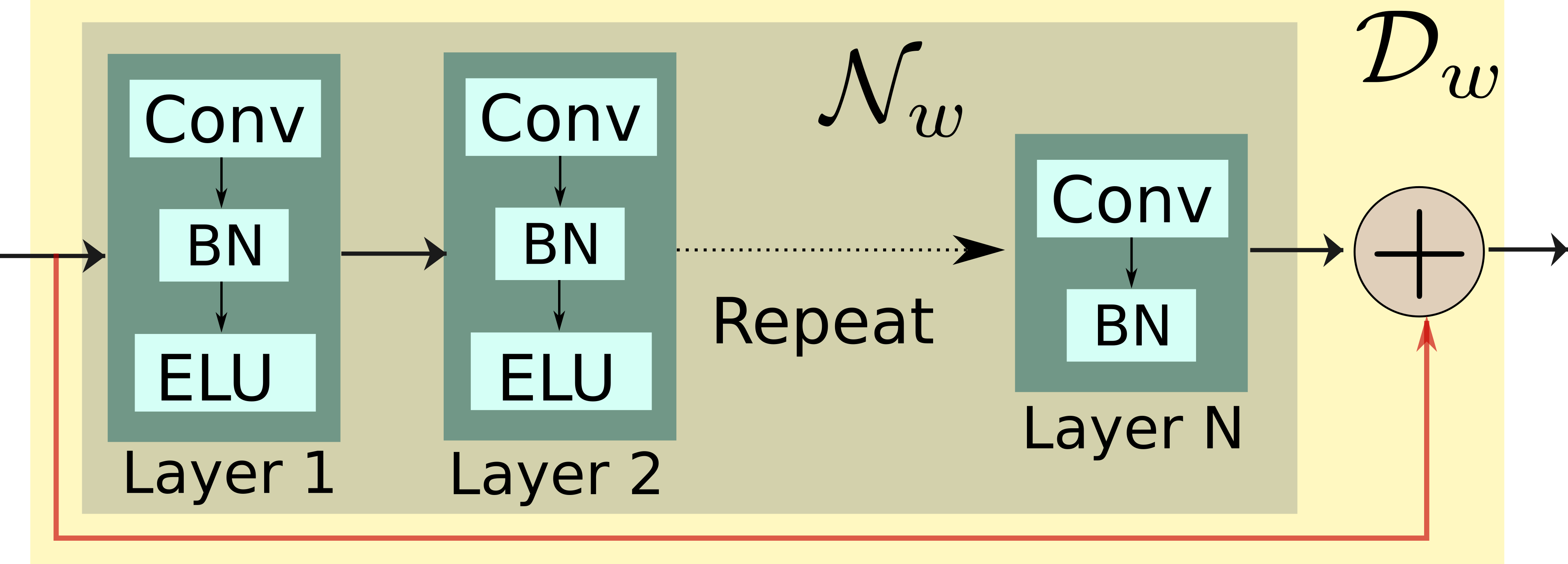
To realize a fast algorithm, we replace the denoiser in (1) with a pre-learned deep residual denoiser $$$D_w$$$ (see Fig. 2) $$\text{Deep Learned D}_w\text{ step: } \mathbf Z_{n+1}= (\mathcal I -\mathcal N_{w}) (\widehat{\mathbf P}_{n+1}) = \mathcal D_w (\widehat{\mathbf P}_{n+1})$$The algorithm alternates between the denoiser and $$ \text{DC step: } \widehat{\mathbf P}_{n+1}= (\mathcal{A}^H\mathcal{A} + \beta I) ^{-1}(\mathcal{A}^H\mathbf y+\beta \mathbf {Z_n} ) $$ The above DC step is implemented using a conjugate gradient algorithm, which acts as a network layer. The proposed method is summarized in Fig. 3. We learn the filter parameters of the unrolled network from exemplary data in an end-to-end fashion as in MoDL$$$^2$$$.
Experiments and Results
To test Deep MUSSELS, we collected in-vivo diffusion data from a healthy volunteer (3T MRI scanner, 32-channel head coil). A 4-shot dual spin-echo diffusion sequence was used with b-value of 1000 s/mm2, 60 diffusion gradients were performed with NEX=2 to improve the SNR. The phase errors associated with the various slices are very distinct due to the cardiac, pulsatile and respiratory motions affecting the different slices of the brain differently. Thus our training and testing datasets consist of 360 and 120 slices respectively with very distinct phase errors.
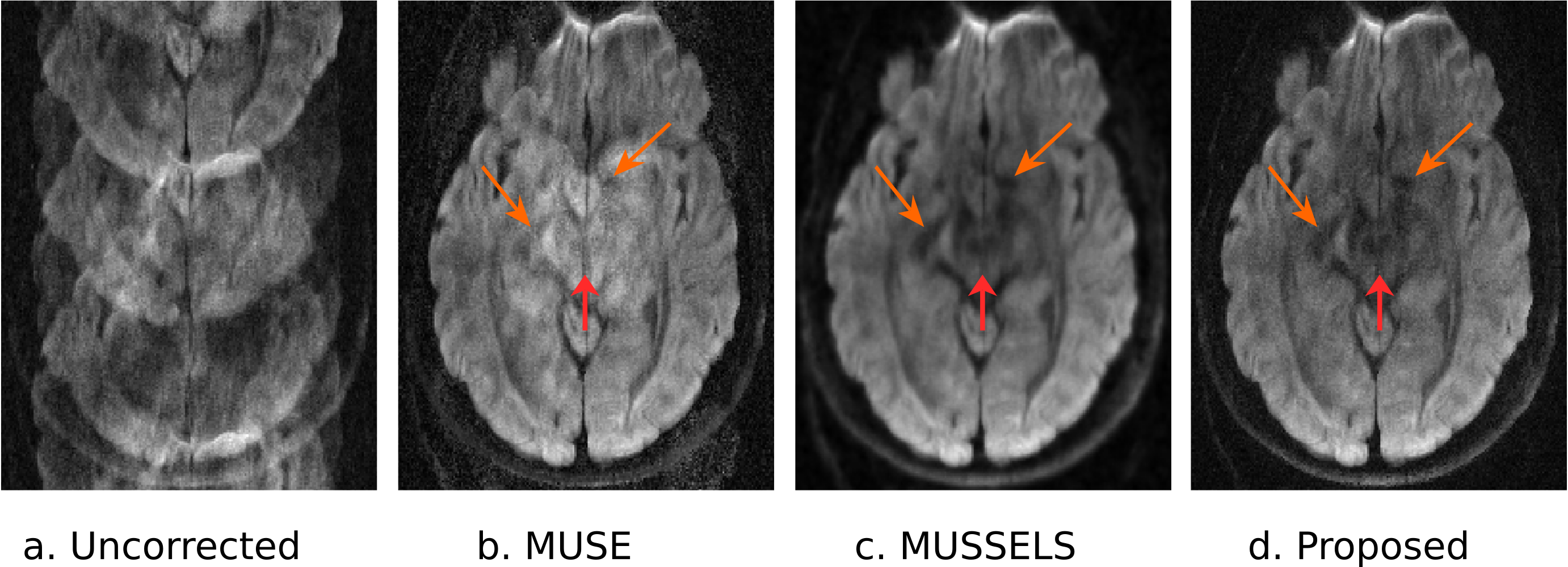
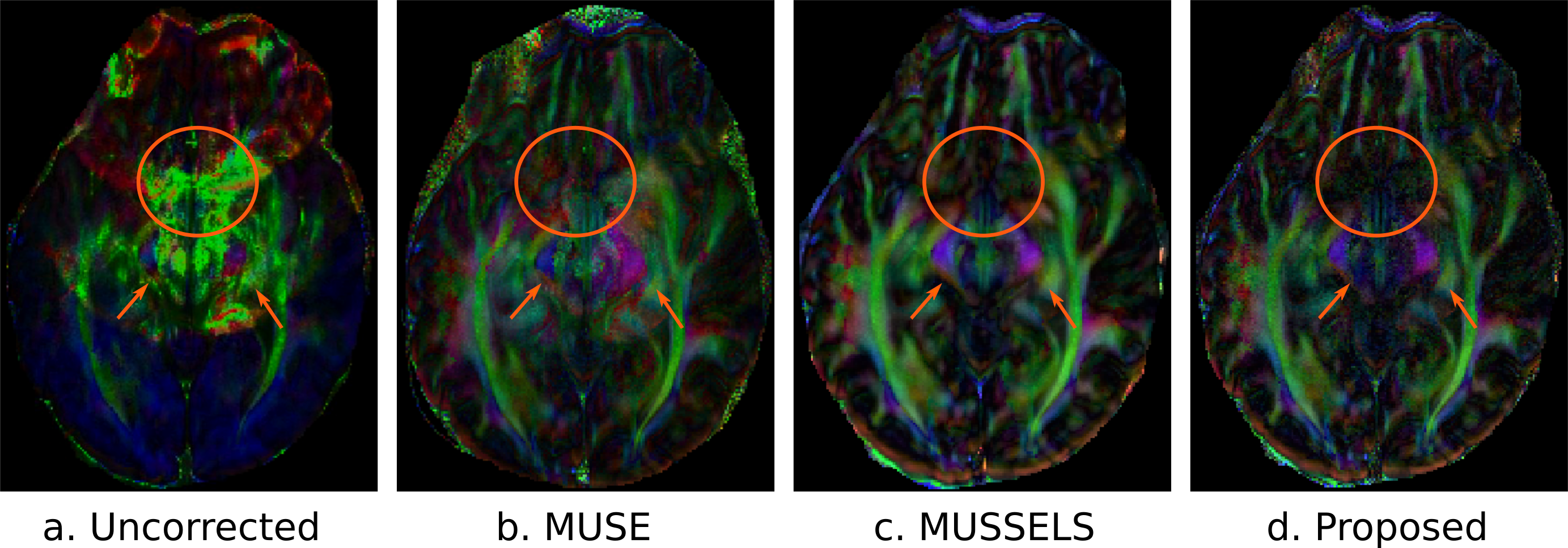
The model training was performed for approximately two hours using TensorFlow on Nvidia P100 GPU. The MUSSELS reconstruction was considered as the ground truth data and the mean-square error between the CNN based reconstruction and MUSSELS reconstruction was minimized during the training. Figure 4 and 5 shows reconstructed images and the FA maps respectively for a particular slice. The testing time to reconstruct one average of a single slice with 60 directions and 4 shots was 2700 sec using MUSSELS and 6 seconds using the proposed deep learning based approach leading to a 450 fold lower computational complexity. The greatly reduced runtime is expected to facilitate the deployment of the proposed algorithm on clinical scanners.
Conclusions
We introduced a model-based deep learning framework for the compensation of phase errors in multishot diffusion-weighted MRI data. The proposed scheme alternates between CNN denoisers and conjugate gradient optimization algorithm to enforce data consistency. The CNN parameters are learned from exemplary data. The preliminary experiments show that the proposed scheme can yield state-of-the-art results while offering several orders of magnitude reduction in run-time.Acknowledgements
No acknowledgement found.References
- Merry Mani, Mathews Jacob, Douglas Kelley, and Vincent Magnotta, “Multi-shot sensitivity-encoded diffusion data recovery using structured low-rank matrix completion (MUSSELS),” Mag. Reson. in Med., vol. 78, no. 2, pp. 494–507, 2016.
- Hemant K Aggarwal, Merry P Mani, and Mathews Jacob, “MoDL: Model-based deep learning architecture for inverse problems,” IEEE Trans. Med. Imag., pp. 1–1, 2018,10.1109/TMI.2018.2865356.
Figures
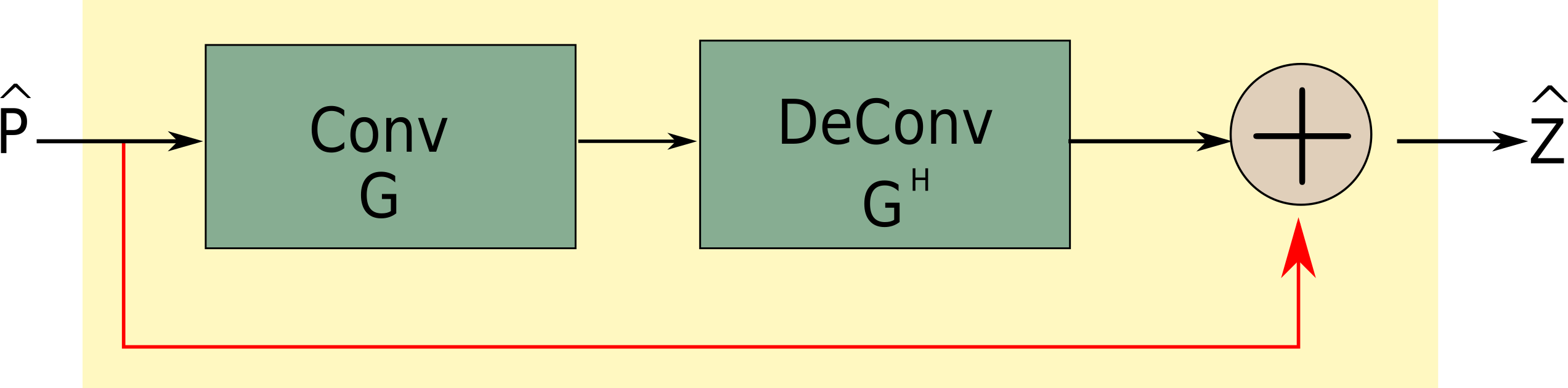
Fig. 1: The network representation of the denoising step of IRLS based formulation in Eq. 1. for self-learnable convolution filters. Conv and DeConv represent convolution and its transpose operations respectively.