0473
Using deep reinforcement learning to actively, adaptively and autonomously control a simulated MRI scanner1Centre for Advanced Biomedical Imaging, University College London, London, United Kingdom
Synopsis
In deep reinforcement learning (DRL), software agents based on deep neural networks are used to explore environments in order to maximise a reward (e.g. score in a video game). Here, DRL was used to control a virtual MRI scanner and actively interpret acquired data. An environment was constructed in which correctly determining the shape of a phantom was rewarded with a high score, and penalised by increasing acquisition time. Following training, the algorithm had learnt to acquire sparse images, assigning TE, TR and flip angles that enabled it to act as an edge detector and deduce shape with 99.8% accuracy.
Introduction
Deep reinforcement learning (DRL) is a subset of machine learning, in which algorithms actively interact with a given environment, aiming to maximise a notional reward or score. This contrasts with more widely used supervised learning approaches, in which algorithms are trained to map input data (such as clinical images) to human expert interpretations (e.g. diagnoses or the location of tumours). DRL was recently brought to prominence by DeepMind (now owned by Google), whose algorithms learnt to play Atari computer games to expert levels, using only pixel data as input1 and to beat world-class experts at the board game Go.2
Here, we report the results of a proof-of-concept study to investigate the ability of deep reinforcement learning to perform real-time, adaptive control of a virtual MRI scanner. The problem was cast in the form of a game, in which an MRI scanner was simulated with the Bloch equations. The objective of the game was to learn to acquire MRI data in a manner that enable the shape of a phantom to be determined (either circle or square), as quickly as possible, guided by partially reconstructed magnitude images.
Methods
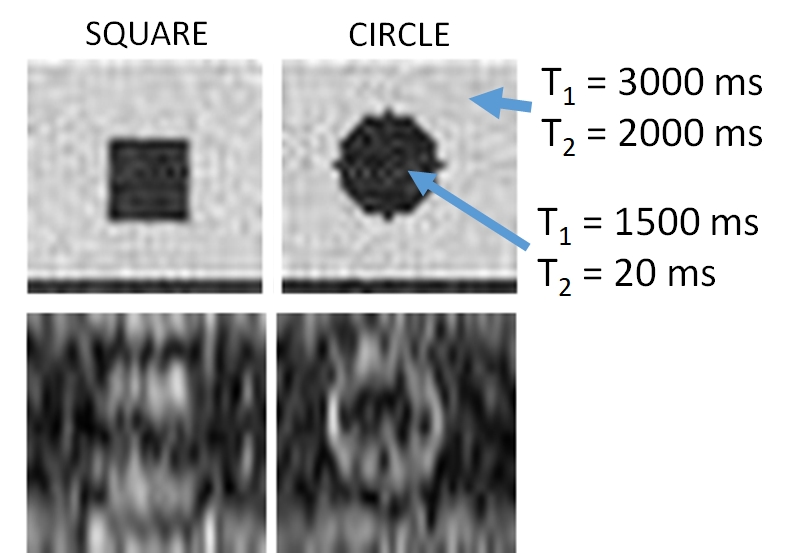
Game environment: A simple, single-slice gradient echo sequence was simulated using the Bloch equations, coded in Python 3.5. In each round of the game, a virtual, square or circular phantom was generated at a random position in a 32×32 2D matrix. Phantoms were assigned T1/T2 = 1300/20 ms. Background regions outside the phantom were assigned T1/T2 = 3000/2000 ms. Equilibirum magnetisation was set to unity and aligned with B0. Gaussian noise was added to the simulated data with a standard deviation of 0.05.
At each step in the game, values for the TR, TE, flip angle and phase-encoding gradient magnitude could be assigned, followed by a readout gradient, during which the virtual signal was sampled, used to fill the appropriate line in k-space, and the image reconstructed using a 2D Fourier transform. Also at each step, the shape of the phantom could be guessed, or left as ‘unknown’. A positive score was granted for a correct shape guess (G+, inversely weighted by total time taken), zero score for no guess (G0), and a large negative score for an incorrect guess (G-).
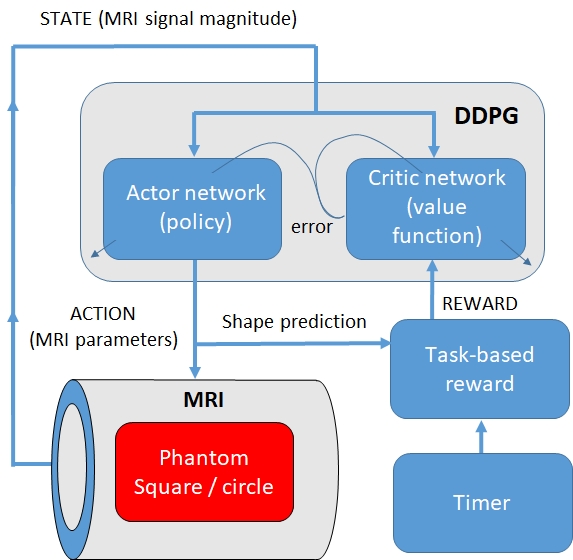
Control with DRL: The deep deterministic policy gradient (DDPG) algorithm with actor-critic architecture 3 was implemented in Keras (Python 3.5), with magnitude pixel data input to the network (see Figure 1). The actor network consisted of 6 2D convolutional layers (widths 32, 32, 64,64,128,128) and 3 dense layers, with 20% dropout and ReLU outputs. The output layer contained 5 nodes corresponding to phase encoding step (PE), TE, TR, flip angle and shape guess (G), which were scaled to the range PE=(0,31), TE=(5,20)ms, TR=(25,2000)ms, flip=(1,90)°. Training was undertaken on 6×106 games, using an NVidia TitanX GPU. The resulting network was evaluated for 10,000 games.
Results
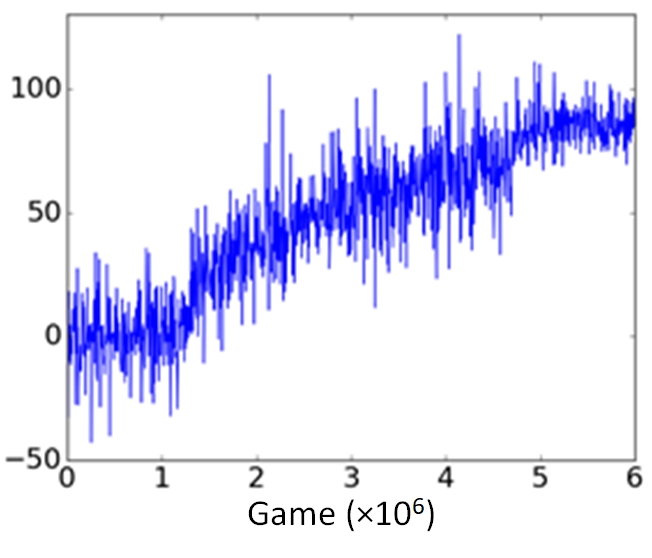
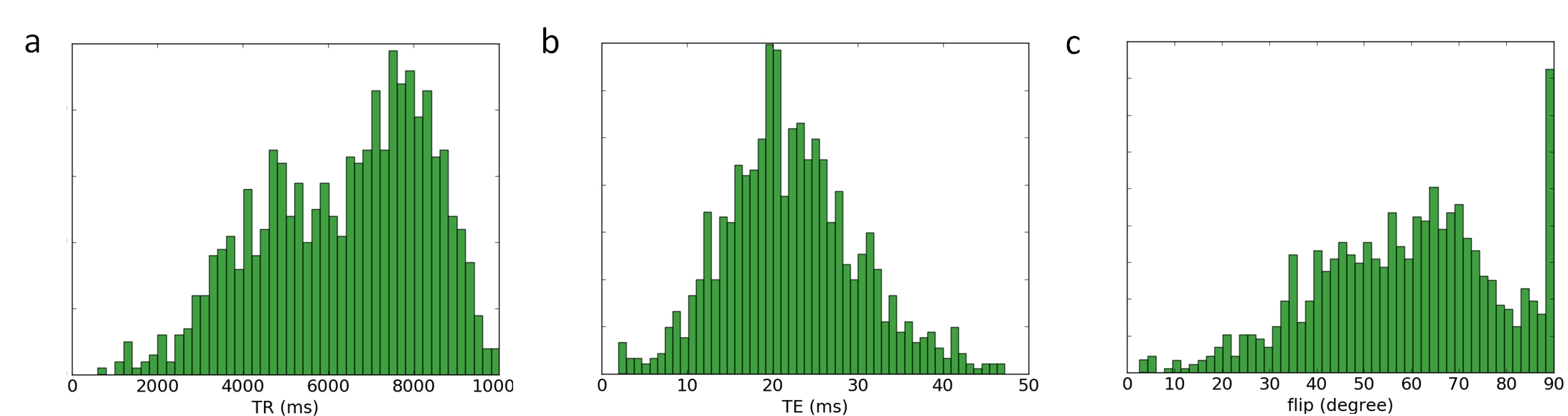
During training of the DRL algorithm, the score increased from 0 to a maximum of ~90, indicating learning by the network (Figure 2). After training, during evaluation, square and circular phantoms were distinguished with 99.8% accuracy, by acquiring between 4 and 6 outer lines of k-space. Example images of virtual phantoms and example images acquired by the DRL algorithm are shown in Figure 3; a movie of the algorithm controlling the virtual scanner can be found at http://goo.gl/dQV75y. During evaluation of the algorithm, mean TR was 6.5±2.3s, mean TE was 20.5±10.3ms, providing a good compromise between image contrast and SNR (Figure 4).Discussion
Without expert human guidance, the DRL algorithm deduced acquisition strategies that enabled the shape of virtual phantoms to be accurately determined. It acquired the outer lines of k-space with TE, TR and flip angle values that enabled contrast between the phantom and the background signal to be generated. The TR selected offered a good compromise between acquisition time (which was penalised by the game) and SNR. Interestingly, the algorithm varied the acquisition parameters during games, introducing mixed weighting into images. Alternative, more complex versions of the game environment can be developed, specific to particular clinical questions, that could potentially include training with expert human experience. DRL also negates the need to form human-readable images and provides a method for enabling MRI scanners to acquire and interpret MR data autonomously. In analogy with autonomous vehicles, this could allow a mechanism for experience to be shared across multiple instances of the algorithm and accelerate learning.Conclusion
This simple example demonstrates the potential utility of DRL to actively and autonomously control an MRI scanner. The next step will be to implement DRL on a real MRI scanner.Acknowledgements
We acknowledge the support received from the Wellcome Trust (WT100247MA)References
1. Mnih et al. Nature, 2014;518
2. Silver et al Nature, 2015;529
3. Lillicrap et al arXiv:1509.02971
Figures