0472
Deep learning without ground truth: an unsupervised method for MR image denoising and super-resolution1Biomedical Engineering, University of Virginia, Charlottesville, VA, United States
Synopsis
Deep learning has shown great success in MR image segmentation, enhancement and reconstruction. However, most methods, if not all, rely on a pair of the input image and the ground-truth image to train the network for a given task. In practice, it is often hard to get the corresponding ground-truth MR images due to limitations in data acquisition. In this study, we aim to use the convolutional neural network (CNN) structure itself as a constraint without using ground-truth images in an optimization task and to evaluate its performance in MR image denoising and super-resolution applications.
Introduction
Deep learning has revolutionized many areas from natural image processing to medical image analysis. Its application in magnetic resonance (MR) image segmentation, enhancement and reconstruction has met with great success. However, most methods, if not all, rely on a pair of input image and ground-truth image for a given task and train a network using supervised learning. The generative adversarial (GAN) methods have slightly alleviated this requirement to use non-paired images from two domains. However, in practice, it is often hard to obtain high-quality ground-truth MR images due to limitations in data acquisition. Recently, a study proposed to use a deep image prior in an optimization task with the applications of artifact removal, inpainting, denoising and super-resolution for natural images1 and showed promising results. Instead of relying on the ground-truth images to train a network, the image prior that is embedded in the convolutional neural network (CNN) structure itself was used as the constraint for the given optimization task. In this study, we improved this method and validated it for MR image denoising and super-resolution applications.Methods
In image restoration problems such as denoising and super-resolution, the goal is to recover the original image $$$x$$$ from a corrupted image $$$x_0$$$, which can be formulated as an optimization task given as:
$$min_xE(x,x_0)+R(x)$$
in which $$$E(x, x_0)$$$ is a data consistency term and $$$R(x)$$$ is the prior knowledge or constraint term. Since such tasks are often ill-posed for a unique solution $$$x$$$, the constraint term $$$R(x)$$$ is required to get a reasonable solution. Recently, deep learning methods have been developed to use paired $$$x$$$ and $$$x_0$$$ to train an optimized network to restore $$$x$$$ from $$$x_0$$$ during testing. $$$R(x)$$$ is then embedded in such optimized networks. However, these methods heavily rely on the availability and abundance of the ground-truth $$$x$$$. On the contrary, the popular compressed sensing method uses hand-crafted image sparsity in different domains as the constraint $$$R(x)$$$ and is successful in MR image reconstruction. Combining the two, instead of using a hand-crafted $$$R(x)$$$, the key idea of a deep image prior is to use the CNN structure itself as a constraint and optimize its parameters without paired $$$x$$$ and $$$x_0$$$ with the hypothesis that the output of a CNN given a fixed input satisfies certain requirements such as smoothness and good visual quality. Therefore, the optimization can be expressed as:
$$min_{\theta}E(f_{\theta}(z),x_0)$$
in which $$$f_{\theta}(z)$$$ represents the CNN output with parameters $$$\theta$$$ and input $$$z$$$. As in GAN models, $$$z$$$ is usually sampled from uniform random noise and $$$f_{\theta}(z)$$$ has a similar network structure as the generative network. To get the CNN parameters, $$$\theta$$$ is randomly initialized and optimized using a training process with $$$E(f_{\theta}(z),x_0)$$$ as the loss function. One notable difference with the conventional CNN is that $$$\theta$$$ is dependent on $$$x_0$$$ and is part of the data rather than the model. In the denoising application, $$$E(f_{\theta}(z),x_0)$$$ is the l1 or l2 difference between $$$f_{\theta}(z)$$$ and $$$x_0$$$. If trained long enough, $$$E(f_{\theta}(z),x_0)$$$ will become 0. However, as the CNN structure is found to have low “impedance” for the true image than noise, during the training process, the true image is generated before the noise, so that when stopped early, $$$f_{\theta}(z)$$$ can approximate $$$x$$$ very well. In the super-resolution application, $$$E(f_{\theta}(z),x_0)$$$ is the difference between a down-sampled $$$f_{\theta}(z)$$$ and $$$x_0$$$. From all solutions that can achieve $$$E(x, x_0)=0$$$, the hypothesis is that $$$f_{\theta}(z)$$$, as the output from a CNN, will likely have the best visual quality.
Results
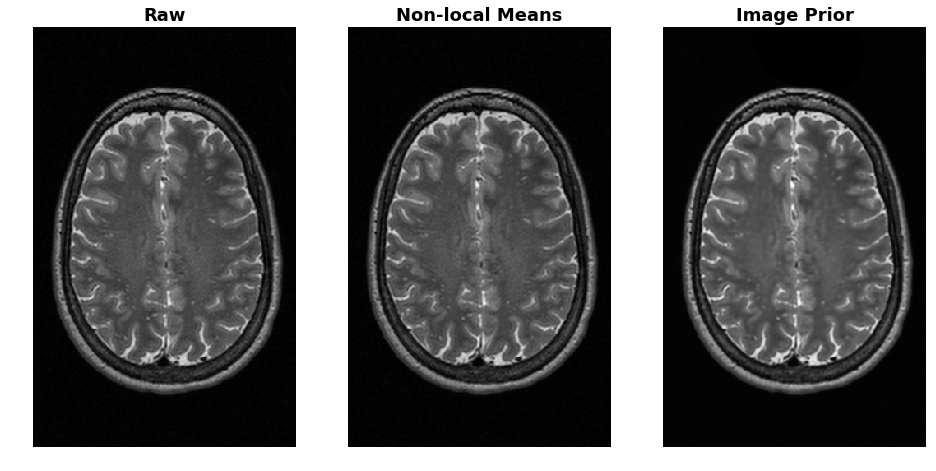
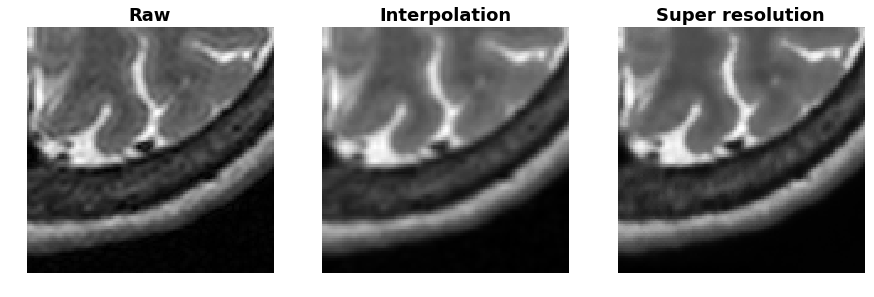
Fig. 1 shows the denoising performance using the proposed method. As a comparison, an adaptive non-local means method was also used2. The image prior method outperformed non-local means and yielded notable improvements in signal-to-noise ratio (SNR) compared with the raw image. Fig. 2 shows the results of the super-resolution experiment, in which the raw image was first down-sampled by 2x and recovered using the proposed method. As a comparison, a simple linear interpolation was also used. The image prior method not only restored the resolution, but also improved SNR as the CNN structure was similar with the one used in denoising.Discussions and Conclusion
We studied MR denoising and super-resolution without ground-truth by using the CNN structure itself as a constraint. The success of CNN in many computer vision tasks gives a strong hint that the structure is well suited to model the complicated images so that it can be used as prior knowledge. Further study for its usage in image reconstruction will be performed.Acknowledgements
No acknowledgement found.References
- Ulyanov D, Vedaldi A, Lempitsky V. Deep image prior. arXiv:1711.10925. [cs.CV]
- Manjon JV, Coupe P, Marti-Bonmati L, et al. Adaptive non‐local means denoising of MR images with spatially varying noise levels. J Magn Reson Imaging. 2010;31(1):192-203.
Figures