0467
Fast Acquisition and Low-delay Reconstruction of Stack-of-stars Trajectory Using Temporal Multiresolution Images and a Convolutional Neural Network1Advanced Technology Research Department, Research and Development Center, Canon Medical Systems Corporation, Yokohama, Japan, 2Software Technologies Group, MRI Systems Development Department, MRI Systems Division, Canon Medical Systems Corporation, Yokohama, Japan
Synopsis
For fast data acquisition and low-delay reconstruction in applications using stack-of-stars trajectory, the authors propose a new reconstruction method using a CNN with temporal multiresolution inputs. Conventionally, stack-of-stars images reconstructed from a few spokes contain streaking artifacts. By utilizing view sharing technique for suppressing the artifacts, reconstructed images are often blurred. For low-delay reconstruction, it is not straightforward to use well-studied methods based on compressed sensing with temporal priors. The proposed method aims to adjust spatio-temporal resolution to a suitable one. Experimental results show that the proposed method could reconstruct highly under-sampled radial dynamic images with reduced artifacts.
Introduction
Fast data acquisition and low-delay reconstruction are fundamental requirements for clinical use of dynamic MRI applications. For fast data acquisition, stack of 2D golden-angle radial trajectories, also known as stack-of-stars trajectory, is a popular method due to its motion robust properties. For reconstructing k-space data acquired with stack-of-stars trajectory, methods using compressed sensing with temporal priors1 have been extensively studied. However, these methods are not suitable for a low-delay reconstruction since evaluation of temporal priors requires many frames (e.g. an entire series of dynamic images).
For low-delay reconstruction, a method using a CNN that utilizes neighboring frames2 has been proposed earlier. While the quality of reconstructed images was better than single-frame solutions, it can be further improved.
Methods
The authors propose a new reconstruction method using a CNN whose inputs are temporal multiresolution images. As shown in Fig. 1, the proposed method reconstructs view-sharing images whose view-sharing factors are 1, 2, …, M as inputs of the CNN.
In dynamic imaging, there is an inherent trade-off between temporal and spatial resolution. To improve temporal resolution, typically stack-of-stars data are acquired with reduced number of spokes. However, these under-sampled images suffer from artifacts. By utilizing view sharing technique for suppressing the artifacts, reconstructed images are often blurred. Existing view-sharing techniques adjust temporal resolution by trial-and-error3. The proposed method aims to adjust temporal resolution to a suitable one.
The proposed method reconstructs a single image from consecutive N frames which includes past and future $$$(N-1)/2$$$ frames. Dynamic images are reconstructed in a frame-by-frame manner. To minimize time delay of reconstruction, first each input image is reconstructed using a (non-iterative) gridding algorithm. Then this image is fed into a CNN. The proposed CNN consists of convolution layers, rectified linear units (ReLUs) and dense connections4 as shown in Fig. 2. The CNN was trained by adaptive moment estimation (Adam)5 with a mean-squared-error loss function. The number of epochs was 100. The parameters of Adam were $$$\alpha=0.001$$$, $$$\beta_1=0.9$$$ and $$$\beta_2=0.999$$$.
For the cases of 13, 21, and 34 spokes per frame, the proposed method was compared with conventional methods using a CNN from a frame to a frame (1-to-1) and a CNN from 5 frames to a frame (5-to-1)2. In all experiments, the proposed method used 5 consecutive frames from 5 neighboring slices, i.e. $$$M=5$$$ and $$$N=5$$$.
For simulations, 8 volunteer images (7 training and 1 test image) were acquired with 3-dimensional fast spoiled gradient echo, T1-weighting, Cartesian trajectory, $$$256 \times 256 \times 32$$$, 24 frames and additional navigator signals. They were sorted retrospectively using the navigator signals and reconstructed as dynamic ground-truth images. A set of k-space data was simulated by applying a non-uniform FFT with a stack-of-stars trajectory to the dynamic ground-truth images.
For evaluating the proposed method with actual stack-of-stars data, 7 volunteer images (6 training and 1 testing images) were acquired with 3-dimensional fast spoiled gradient echo, T1-weighting, a stack-of-stars trajectory with 256 readout points and 32-40 slice encodes. For each volunteer, 3000-4000 spokes were acquired. They were reconstructed as both dynamic images with 13, 21, and 34 spokes per frame and a single ground-truth image.
Results
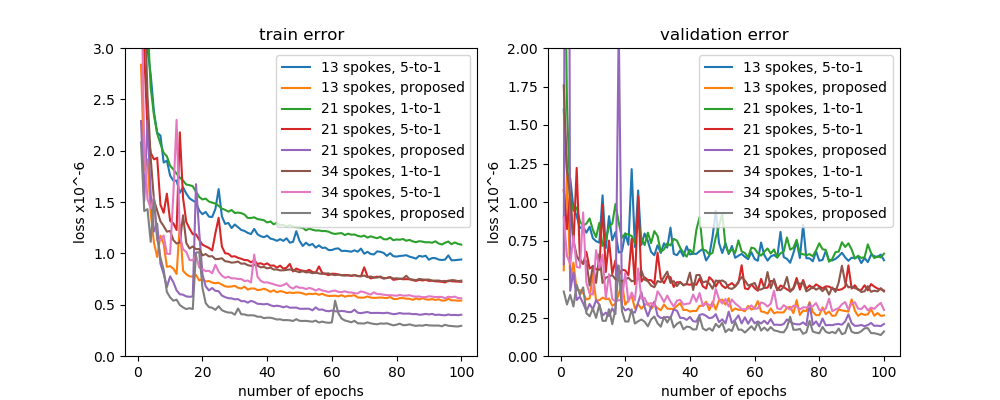
As shown in the loss curves using simulated data (Fig. 3), the proposed method gave lower training and validation loss values (i.e. mean squared errors) than the conventional 1-to-1 and 5-to-1 methods. In addition, the proposed method with 13 spokes per frame was lower validation error than even the 5-to-1 method with 34 spokes per frame. This means that the proposed method can give better image quality at a higher temporal resolution than conventional methods. The results for both simulated data (Fig. 4) and actual stack-of-stars data (Fig. 5) showed that liver structures reconstructed by the proposed method were more clearly depicted by using the proposed method.Discussion
The results showed that the proposed method reconstructed dynamic images with reconstruction delay of 2 ($$$=(N-1)/2$$$) future frames and processing time using gridding reconstruction of 5 ($$$=N$$$) images ($$$N(N+1)/2$$$ images for the first frame).
For evaluation using actual stack-of-stars data, the CNN was trained as a map from all dynamic images in a slice to a single ground-truth image in the slice. Evaluation using dynamic ground-truth images needs an acquisition with a high temporal resolution and is considered as a future work.
Conclusion
The authors propose a new reconstruction method using a CNN with temporal multiresolution inputs. The proposed method aims to adjust temporal resolution to a suitable one. Experimental results showed that the proposed method could acquire highly under-sampled radial dynamic images and reconstruct them with small time delay.Acknowledgements
The authors thank all volunteers for their participations.References
1. L. Feng et al. Golden-Angle Radial Sparse Parallel MRI: Combination of Compressed Sensing, Parallel Imaging, and Golden-Angle Radial Sampling for Fast and Flexible Dynamic Volumetric MRI. Magnetic Resonance in Medicine. 2014; 72(3): 707–717.
2. H. Takeshima. Integrating Spatial and Temporal Correlations into a Deep Neural Network for Low-delay Reconstruction of Highly Undersampled Radial Dynamic Images. Proc. Intl. Soc. Mag. Reson. Med. 2018; 26: 2796.
3. T. Song et al. Optimal k-space Sampling for Dynamic Contrast-enhanced MRI with an Application to MR Renography. Magnetic Resonance in Medicine. 2009; 61: 1242-1248.
4. G. Huang et al. Densely Connected Convolutional Networks. IEEE Conference on Computer Vision and Pattern Recognition. 2017; 2261-2269.
5. D. Kingma et al. Adam: A Method for Stochastic Optimization. arXiv: 1412.6980.
Figures