0466
Generation of globally consistent non-confidential MRI data using deep generative adversarial networks1Institute of Signal Processing and System Theory, University of Stuttgart, Stuttgart, Germany, 2Radiology Department, University Hospital Tübingen, Tübingen, Germany
Synopsis
The lack of easily accessible open-source medical datasets is one of the biggest limiting factors to advance the development of deep models for any medical task. In this work, we utilize
Introduction
Due to the enormous number of parameters in deep learning architectures, a huge amount of data is needed to obtain high performing models. This is especially a challenge in the medical domain, since there is only limited data available and most importantly due to the confidentiality of medical data. It is often difficult or even impossible for researchers to get access to medical datasets due to restrictive copyright and patient privacy agreements. A possible solution is to utilize deep generative models to learn medical data distributions and generate open-source MRI data with no sensitive patient information. The availability of such non-confidential datasets would push further research and improve existing deep models for medical tasks.
There are multiple existing deep generative models. Auto-regressive generative models such as PixelRNN1, or PixelCNN++2 can generate realistic images. However, they are incapable of generating high-resolution images due to being exceedingly computational expensive. In this study, we use state-of-the-art generative adversarial networks3 (GANs) which have been proven to produce images with sharper edges compared to variational autoencoders4.
Methods
In a GAN3 setting, two models are trained simultaneously. The generator learns to capture the data distribution, whereas the discriminator estimates the probability that a sample is real or fake.
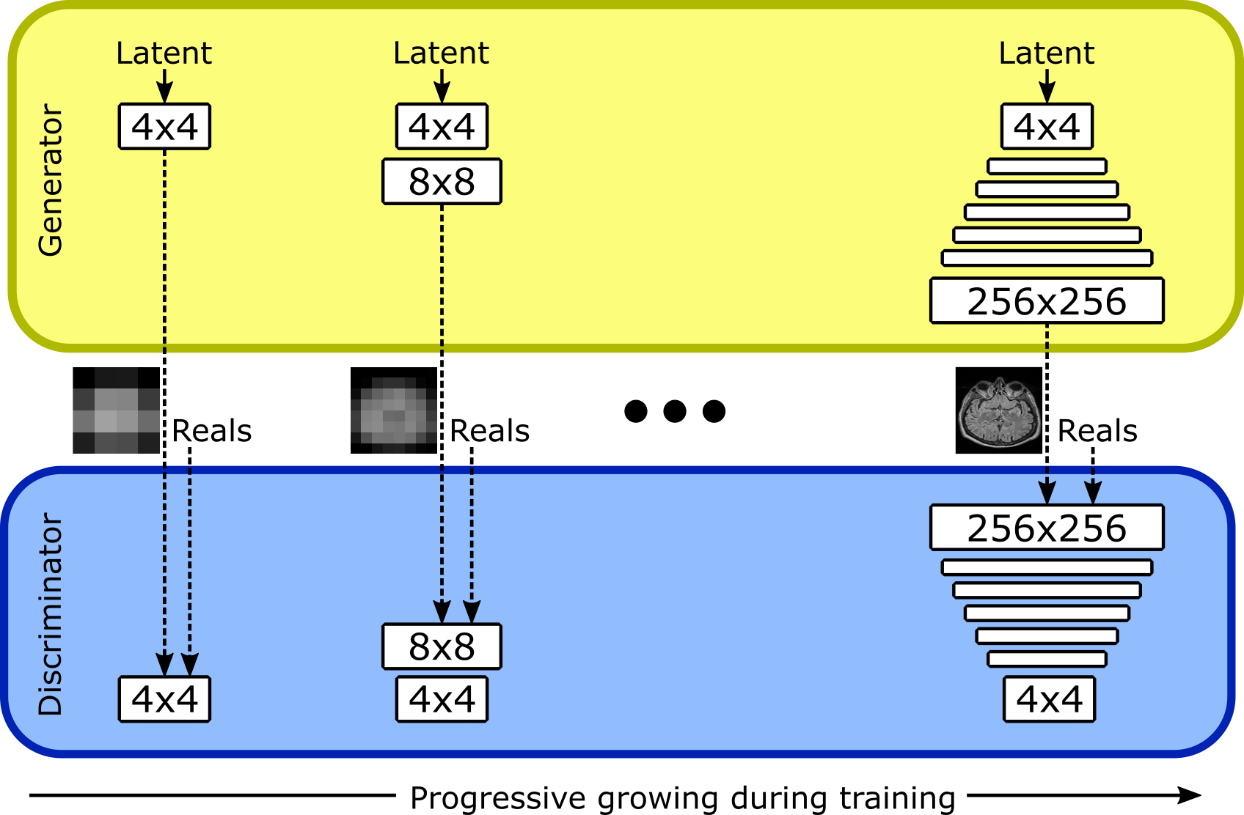
The baseline Progressive Growing of GANs5 (ProGAN) is illustrated in Fig. 1. WGAN-GP loss6 and weight scaling at runtime are used. Moreover, pixel-wise feature vector normalization is used in the generator and minibatch standard deviation in the last block of the discriminator5.
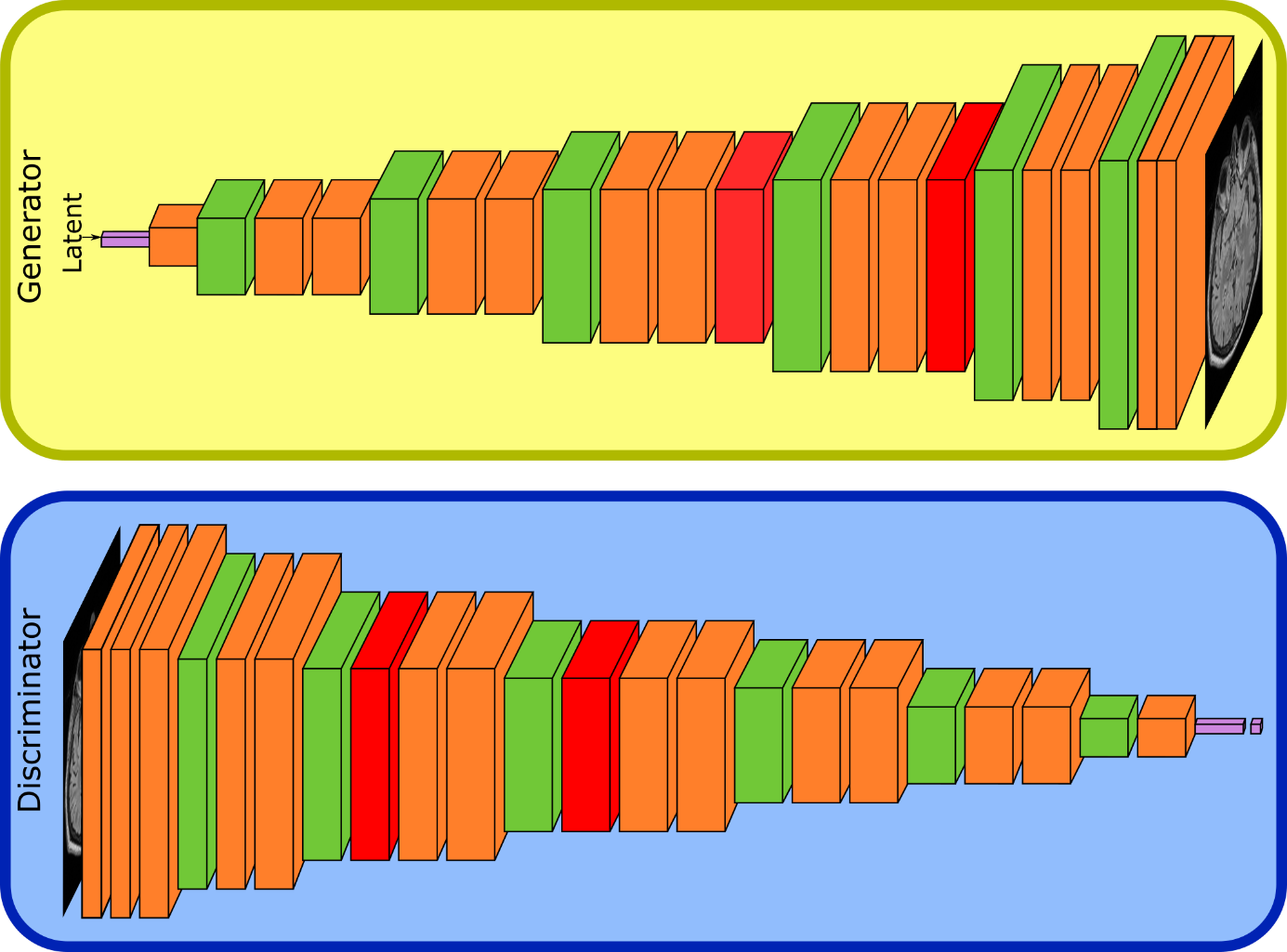
Most GAN models are built using convolutional layers, which process information in a local neighbourhood. Stacking convolutions increases the receptive field, but is inefficient for modelling long-range dependencies which may result in global inconsistencies in the generated samples. Self-attention7 is a mechanism to model long-range dependencies efficiently by computing a weighted sum for all input signals. In this work, additional self-attention layers are used in the discriminator. This enables the discriminator to check whether features in distant regions of the image are consistent with each other. Self-attention was already successfully introduced to a different GAN framework8. The placement of the self-attention layers for the proposed architecture is illustrated in Fig. 2.
T2-weighted (FLAIR) MR scans of the head region acquired on a 3T scanner were used. The data were resampled to 1x1x1 mm3 and rescaled to 2D slices of size 256x256 pixels. The training dataset consists of 35,593 MR images from anonymized 232 patients, which are normalized between -1 and 1. Several models were trained. Models (a), (b) and (d) as described in Fig. 2 were trained for 867,000 iterations with a decreasing batch size from 128 to 8, according to the resolution. Model (b) was trained for an additional 375,000 thousand iterations with a reduced learning rate and is denoted as model (c).
Results
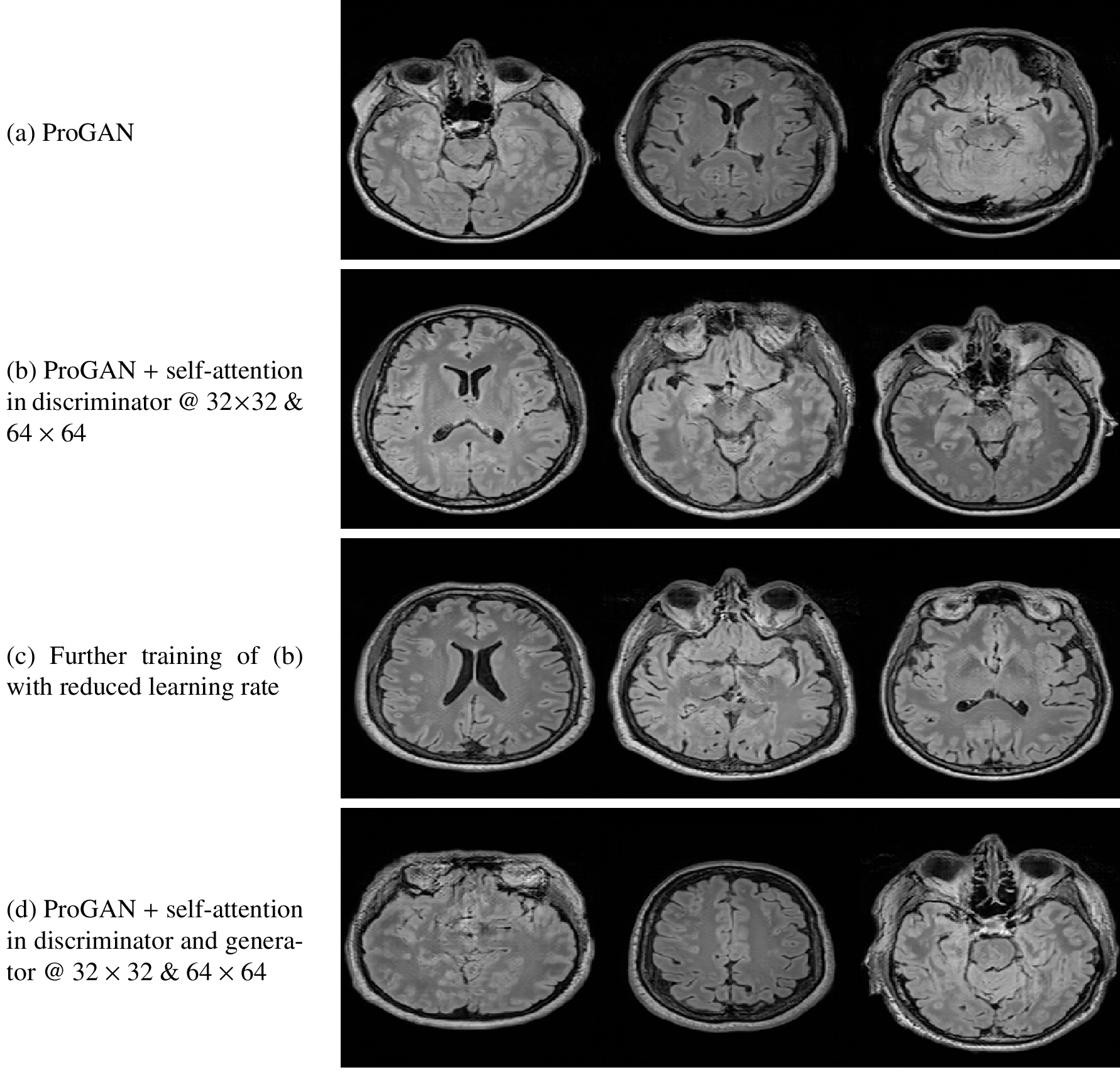
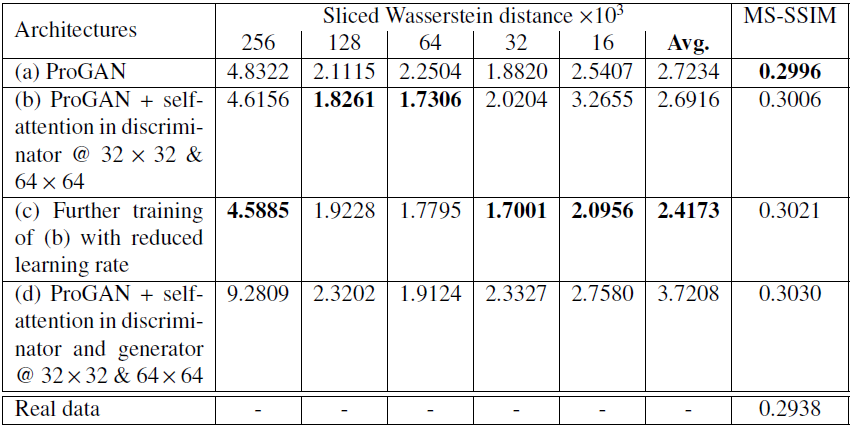
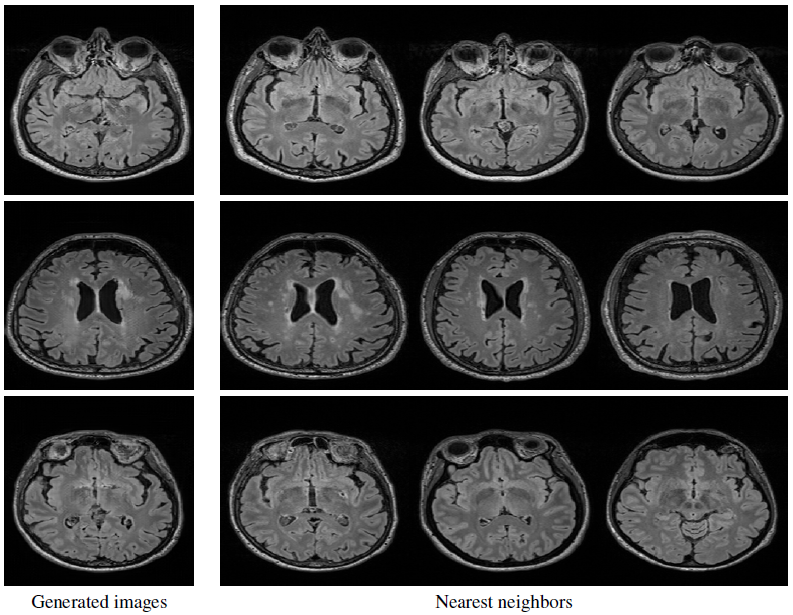
Qualitative and quantitative evaluations were carried out to assess the performance of the proposed models. Generated MRI samples are presented in Fig. 3. The Multiscale Structural Similarity9 (MS-SSIM) is computed between 20,000 randomly chosen generated image pairs to ensure that the generated dataset has the same level of diversity as the training dataset. Quantitative results in Fig. 4 show there is no mode collapse for all models. Furthermore, the Sliced Wasserstein Distance5 (SWD) is used to quantitatively measure the overall generated sample quality. It compares the distributions of local image patches drawn from a Laplacian pyramid sampling from the training and generated images. Results are shown in Fig. 4. Using self-attention in the discriminator drastically increases global consistency. To investigate if the generator produces novel images or just memorizes the training images, nearest neighbours are shown for a few examples in Fig. 5. There is no memorization, therefore the generated examples can be treated as non-confidential.Discussion
Adding self-attention layers in the discriminator improves the performance significantly compared to the baseline Progressive Growing of GANs by resulting in improved global consistency. Introducing self-attention to the generator degrades the performance of texture synthesis, which might be due to instabilities during training.Conclusion
In this study, we illustrate the potential of deep generative adversarial networks to generate novel, globally consistent, non-confidential MRI data which could potentially be published as open-source.
In the future, we plan to expand the current study via conditional GANs to allow for more degrees of freedom in the choice of the generated images. For instance, the generation of different organ structures, different modalities, healthy or unhealthy data and the extension to 3D image generation.
Acknowledgements
No acknowledgement found.References
1: A. van den Oord, N. Kalchbrenner, and K. Kavukcuoglu, "Pixel recurrent neural networks", in International Conference on Machine Learning, 2016.
2: T. Salimans, A. Karpathy, X. Chen, and D. P. Kingma, "Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications", arXiv preprint, 2017.
3: I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, "Generative Adversarial Networks", in Conference on Neural Information Processing Systems, 2014.
4: D. P. Kingma and M. Welling, "Auto-Encoding Variational Bayes", arXiv preprint arXiv, 2013.
5: T. Karras, T. Aila, S. Laine, and J. Lehtinen, "Progressive Growing of GANs for Improved Quality, Stability, and Variation", in International Conference on Machine Learning, 2018.
6: I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. Courville, "Improved Training of Wasserstein GANs", in Conference on Neural Information Processing Systems, 2017.
7: X. Wang, R. B. Girshick, A. Gupta, and K. He, "Non-local neural networks", in Conference on Computer Vision and Pattern Recognition, 2018.
8: H. Zhang, I. Goodfellow, D. Metaxas, and A. Odena, "Self-Attention Generative Adversarial Networks", in arXiv preprint, 2018.
9:
A. Odena, C. Olah, and J. Shlens, "Conditional image synthesis with auxiliary classifier GANs" in International Conference on Machine Learning,
2017.
Figures