0017
High-resolution 3D MR Fingerprinting using parallel imaging and deep learning1Radiology, University of North Carolina at Chapel Hill, Chapel Hill, NC, United States, 2Biomedical Research Imaging Center, University of North Carolina at Chapel Hill, Chapel Hill, NC, United States
Synopsis
In this study, a high-resolution 3D MR Fingerprinting technique, combining parallel imaging and deep learning, was developed for rapid and simultaneous quantification of T1 and T2 relaxation times. Our preliminary results show that, with the integration of parallel imaging and deep learning techniques, whole-brain quantitative T1 and T2 mapping with 1-mm isotropic resolution can be achieved in ~6 min, which is feasible for routine clinical practice.
Introduction
MR Fingerprinting (MRF) is a relatively new imaging framework which can provide accurate and simultaneous quantification of multiple tissue properties for improved tissue characterization and disease diagnosis (1,2). While most of the current studies are performed using 2D MRF, extension to 3D MRF can provide a higher spatial resolution and better tissue characterization with an inherently higher signal-to-noise ratio. However, 3D MRF with a high spatial resolution requires lengthy acquisition time, especially for a large volume (e.g., whole brain), making it impractical for clinical applications. The aim of this study was to employ parallel imaging and deep learning techniques to develop a rapid 3D MRF method that is capable of achieving 1-mm isotropic resolution and whole brain coverage within a clinical feasible time window.Methods
All measurements were performed on a Siemens 3T Prisma scanner using a 32-channel head coil. We adopted our previously reported 3D MRF approach in the current study (3) and applied to five normal subjects (M:F, 2:3; mean age, 35±10 years). Similar to the original MRF framework, each MRF time frame was highly undersampled in-plane with only one spiral arm (reduction factor, 48). The partition direction is linearly encoded and fully sampled. With a constant TR of 9.2 ms and a waiting time of 2 sec between partitions, the total scan time was ~27 min for each subject. Other imaging parameters included: FOV, 25×25 cm; matrix size, 256×256 (effective in-plane resolution, 1 mm); slice thickness, 1 mm; number of slices, 96; variable flip angles, 5°~12°; MRF time frame, 768.
After the MRF measurements, reference T1 and T2 maps were first extracted from the 3D dataset using pattern matching (1). To evaluate the performance of parallel imaging and deep learning for acceleration, the acquired dataset was retrospectively undersampled by a factor of 2, and 6/8 partial Fourier was also applied along the partition direction. The effect of different number of time frames (128, 192, 256 and 384) was evaluated. An interleaved sampling pattern was used to reduce coherent artifacts along the temporal dimension (4). To reconstruct 3D MRF images, Cartesian GRAPPA was first applied along the partition direction and the GRAPPA weights were calculated from the central ten partitions. These calibration data at k-space center were integrated in the final reconstruction for preserved image contrast.
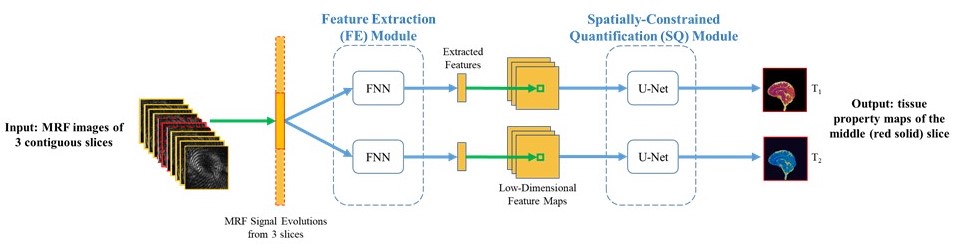
After GRAPPA reconstruction, a convolutional neural network (CNN) previously developed for 2D MRF was modified for 3D MRF application (5). The CNN model includes two major modules, a feature extraction module and a spatially-constrained quantification module (Fig. 1). Reconstructed 3D MRF images from three contiguous slices were used as input, and the reference T1 and T2 maps from the corresponding central slice were used as the output for CNN training. 3D datasets from four volunteers were randomly selected for the training, and the dataset from the remaining subject was used for validation. Standard data augmentation was applied to inflate the training dataset by three times. Normalized root-mean-square error (NRMSE) values were calculated as compared to the reference T1 and T2 maps calculated from the fully sampled dataset. The performance of the proposed method was compared to the two previously published methods for accelerated 3D MRF (4, 6).
Results
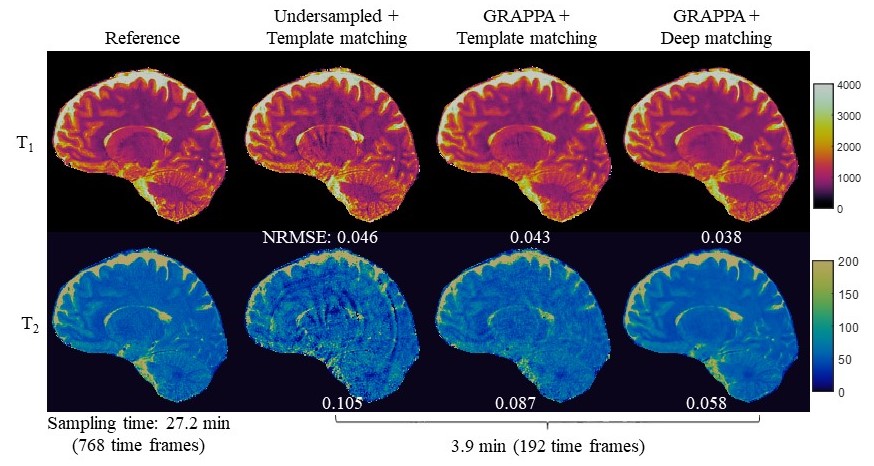
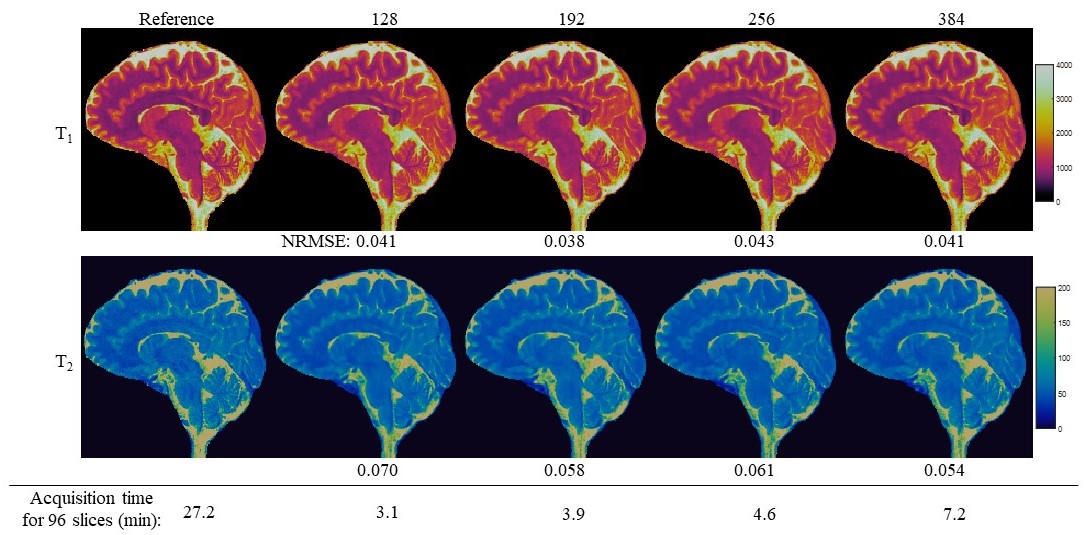
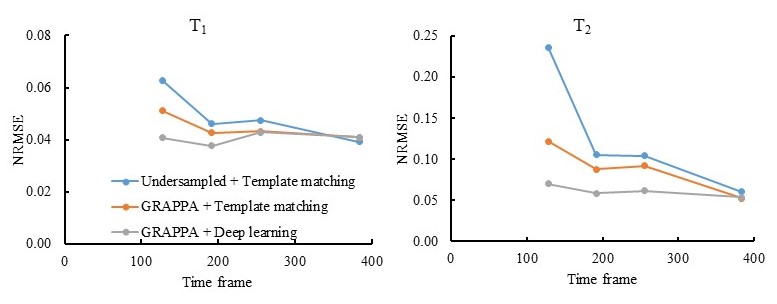
Fig. 2 shows representative results obtained from 192 time frames. Compared to the previously published approaches, lower NRMSE values were observed for both T1 and T2 using the proposed method. Fig. 3 shows representative T1 and T2 maps obtained with different time frames. High quality quantitative maps with 1-mm isotropic resolution were obtained for all the cases, and the sampling time for 96 slices was around 3 min for the case with 128 time frames. The NRMSE values for different time frames and reconstruction methods are summarized in Fig. 4, which demonstrates that the proposed method can be applied for rapid tissue quantification with highly accelerated data sampling in both spatial and temporal dimensions.Discussion and conclusion
In this study, a rapid 3D MRF method with a spatial resolution of 1 mm3 was proposed, which has the potential to provide whole-brain (20-cm volume) quantitative T1 and T2 maps in ~6 min. This is comparable to the acquisition time of conventional T1-weighted or T2-weighted images with similar spatial resolution. By leveraging both parallel imaging and deep learning techniques, the proposed method demonstrates improved performance as compared to previously published methods, such as the interleaved sampling method (4) or parallel imaging alone (6). Future studies will focus on implementation of the method for prospectively undersampled MRF dataset.Acknowledgements
No acknowledgement found.References
1. Ma D, et al. Nature, 2013; 187–192.
2. Yu A, et al. Radiology, 2017; 729-738.
3. Chen Y, et al. Radiology, 2018; in press.
4. Ma D, et al. MRM, 2017; 2190-2197.
5. Fang Z, et al. MLMI 2018.
6. Liao C, et al. NeuroImage, 2017; 13-22.
7. McGivney D, et al. IEEE Trans Med Imaging, 2014; 1-13.
8. Ronneberger O, et al. Medical Image Computing and Computer-Assisted Intervention, 2015; 234–241.
Figures